
0x01 前言
在过去的几天里,我有两台虚拟机不断被检测到IO超时。可是最近并没有对这两台虚拟机做出任何修改,服务器也没有增加虚拟机,肯定是哪里有异常导致的。
0x02 软件
在zabbix监控中,web和node2这两台虚拟机的磁盘IO被报告超时,故障时间长达4天。我的邮件也收了好几百封。因为zabbix每10分钟会复检一次,不能排除故障就发邮件。
邮件内容如下:
虚拟机web:
Trigger: Disk I/O is overloaded on web.t.com Trigger status: PROBLEM Trigger severity: Warning Trigger URL: Item values: CPU iowait time (web.t.com:system.cpu.util[,iowait]): 26.9 %
虚拟机node2:
Trigger: Disk I/O is overloaded on node2.t.com Trigger status: OK Trigger severity: Warning Trigger URL: Item values: CPU iowait time (node2.t.com:system.cpu.util[,iowait]): 15.27 %
web这台虚拟机运行着zabbix server和ELK套件,node2仅运行elasticsearch。
这几天我正对我的网站进行渗透测试,生成了将近5GB的日志。根据以往的情况,logstash和elasticsearch的效率很高,但也不至于使得iowait高达25%到50%。
我登录到服务器中查看filebeat的情况,发现filebeat早已将日志文件传输完毕。同时zabbix对数据库的读写也不至于产生那么高的IO。
以下是web这台虚拟机的IO情况:
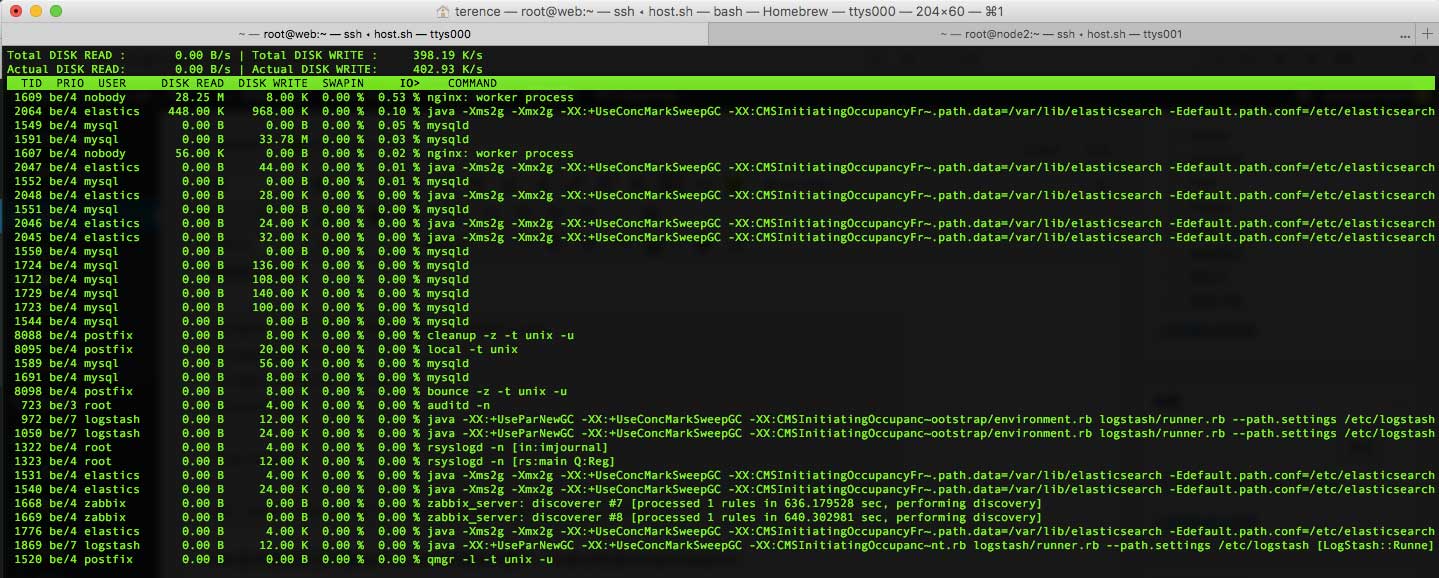
以下是node2的IO情况:
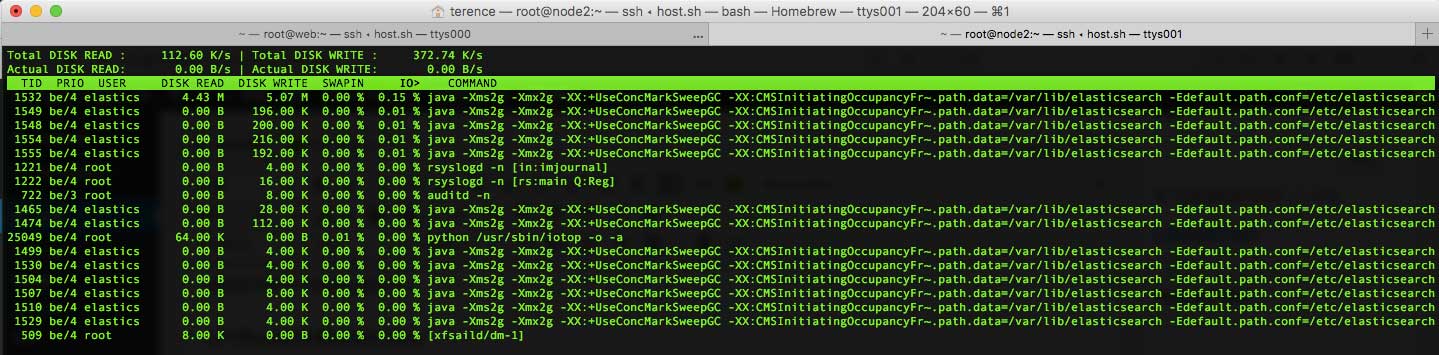
从图中可以看到,读写速度并没有很高,这居然也能报iowait错误。我觉得这应该不是系统问题导致的,所以我转而从硬件入手。
0x03 硬件
我第一个想到的是硬盘坏了,导致阵列被降速。但是我发现服务器背后的状态灯和前部诊断显示器都是正常的蓝色,以下是idrac中关于磁盘的信息:
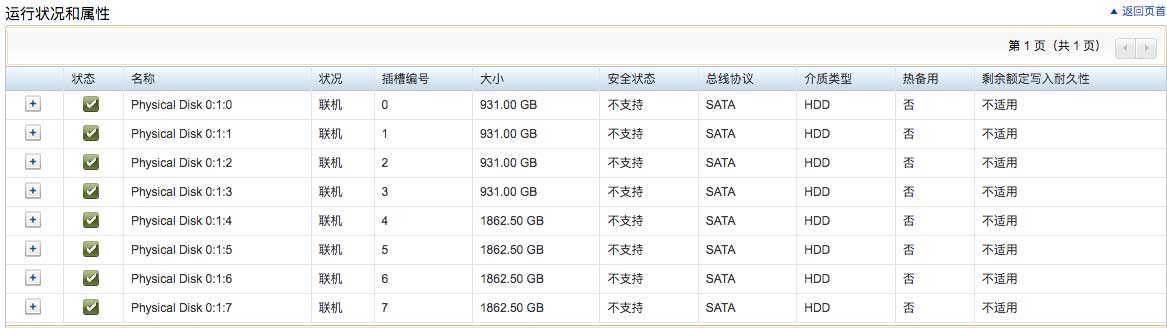
以下是阵列控制器的信息:
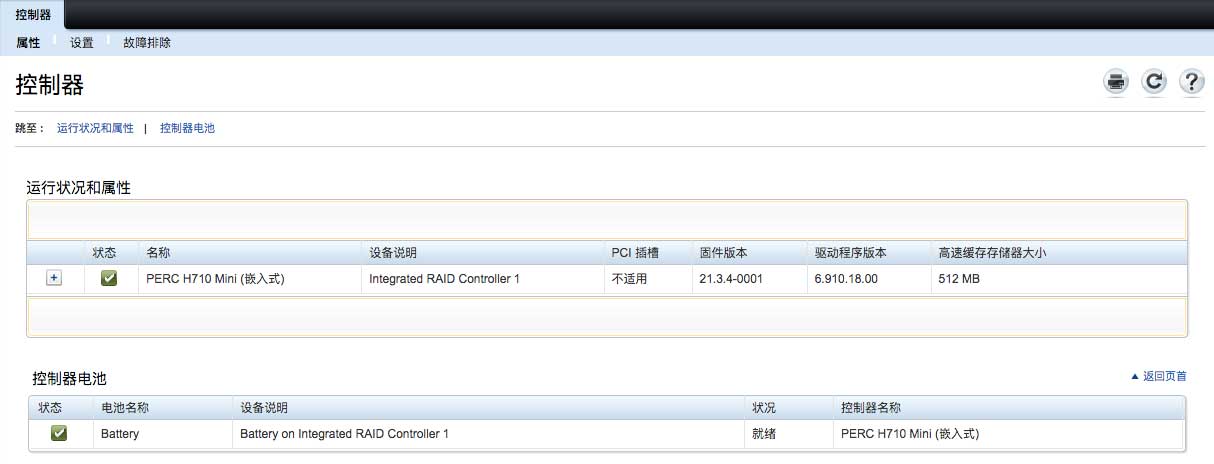
从上面的信息可以确认硬件一些正常。这时候我又检查服务器硬件日志,在 Lifecycle日志中注意到存储日志中有异常情况:
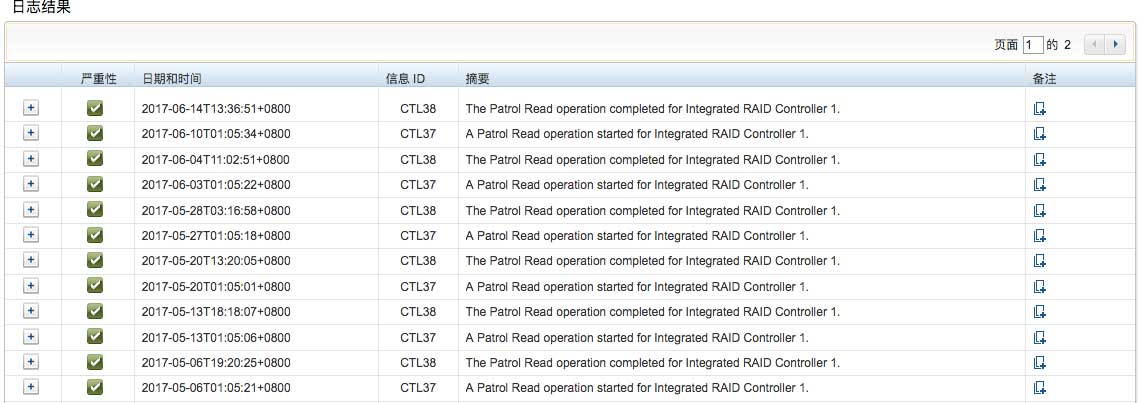
我注意到这个月的10号,服务器的阵列控制器启动了一个名为Patrol Read的任务,直至14号才结束。而zabbix的警告也是从10号到今天才结束。
0x04 Patrol Read
查询资料后发现,Patrol Read是Dell PowerEdge系列服务器阵列卡的一个功能,会定时巡检磁盘,检查数据。主要是为了校验阵列中的数据,以防出错。
但是在巡检的时候会导致磁盘读写性能下降,对服务器的正常运行影响非常大。我不想这功能自动运行,所以我在idrac中将它设为手动,当我有需要的时候手动运行即可。
进入idrac阵列控制器的属性配置界面:
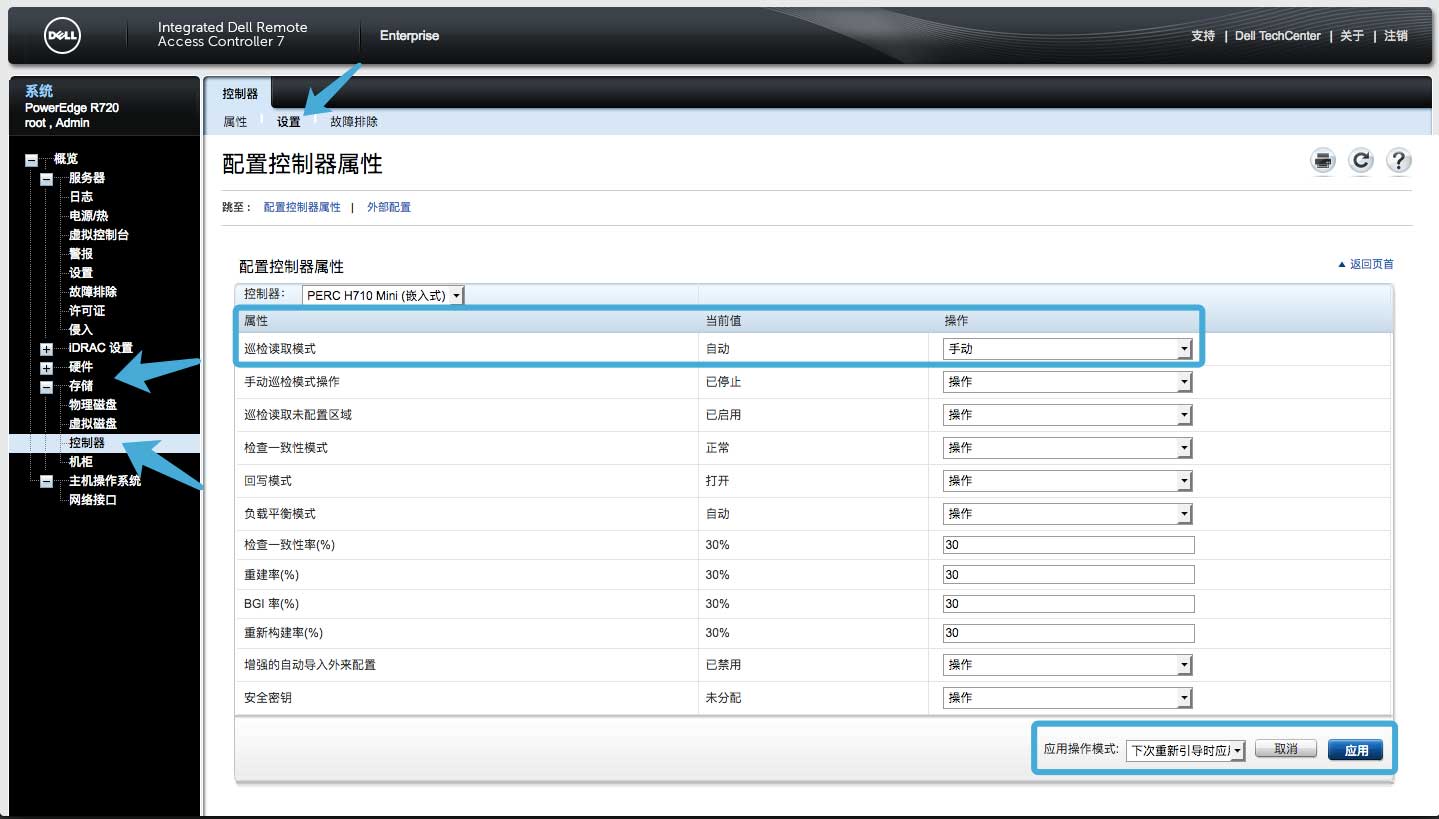
将“巡检读取模式”选为手动,然后将“应用操作模式”按需选择以便新配置应用到系统中。因为我的服务器不能立即关机,只能等到下次重启时才能应用,因此我选择“下次重新引导时应用”。
点击应用后,这个任务会被添加到系统作业队列中:
点击作业队列即可查看现有的任务队列:
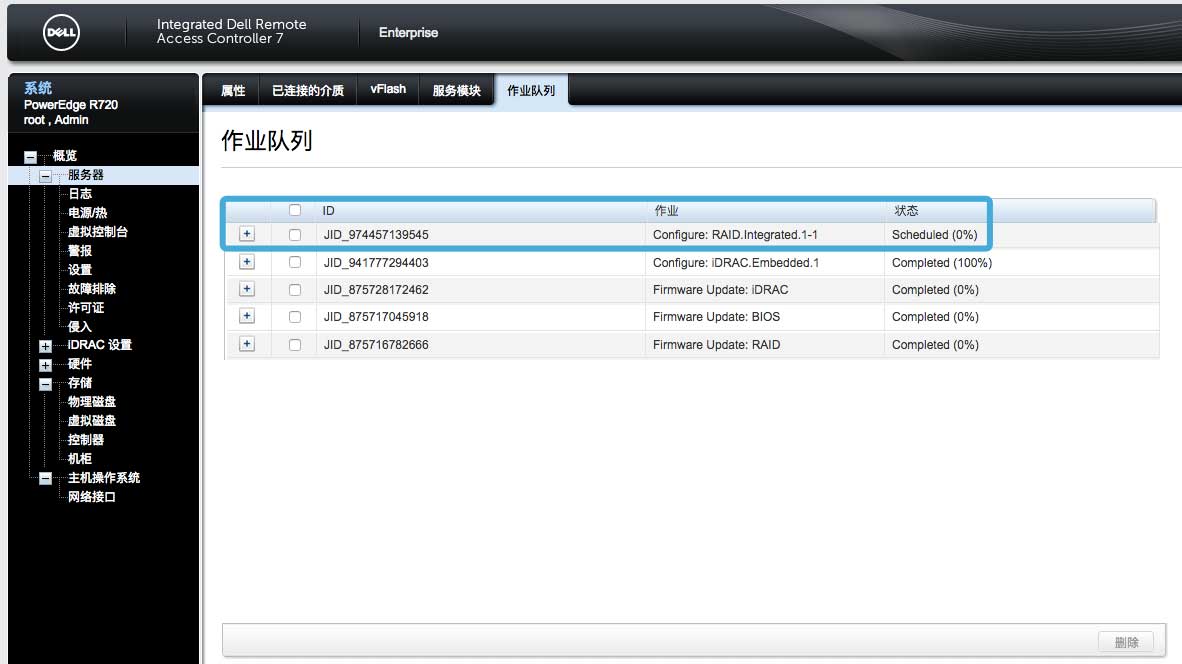
另外,为了日后在有需要的情况下可以手动启动巡检功能,我还需要将“手动巡检模式操作”设为“停止”而不是“禁用”。
0x05 结语
这一次的巡检已经结束,服务器的IO也已经恢复正常。以下是web虚拟机:
Trigger: Disk I/O is overloaded on web.t.com Trigger status: OK Trigger severity: Warning Trigger URL: Item values: CPU iowait time (web.t.com:system.cpu.util[,iowait]): 1.02 %
以下是node2虚拟机:
Trigger: Disk I/O is overloaded on node2.t.com Trigger status: OK Trigger severity: Warning Trigger URL: Item values: CPU iowait time (node2.t.com:system.cpu.util[,iowait]): 0.3 %






















