0x01 前言
在某些直播中计划进行抽奖活动,参加活动就得先报名,统计报名人员的信息是一个非常繁琐的工作。对于“懒到出汁”的我来说,手动统计是不可能的,这辈子都不可能的。
最近一次抽奖活动将在11号的直播中进行,而报名工作在我写这篇文章前就已经结束了,详细规则和其他内容请留意以下文章:
为了实现统计报名人数和“懒”的基本需求,我特意写了一个渣渣的python脚本。
0x02 思路与准备
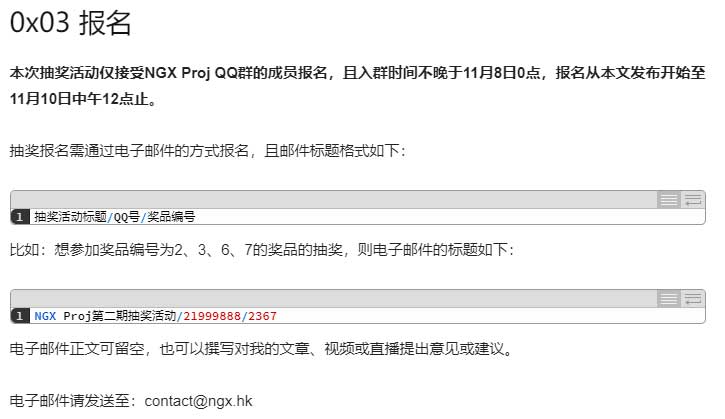
为了方便使用脚本统一处理报名邮件,我针对我的实际情况制定了报名规则。需要编写标题格式如下的邮件并发送到指定的邮箱:
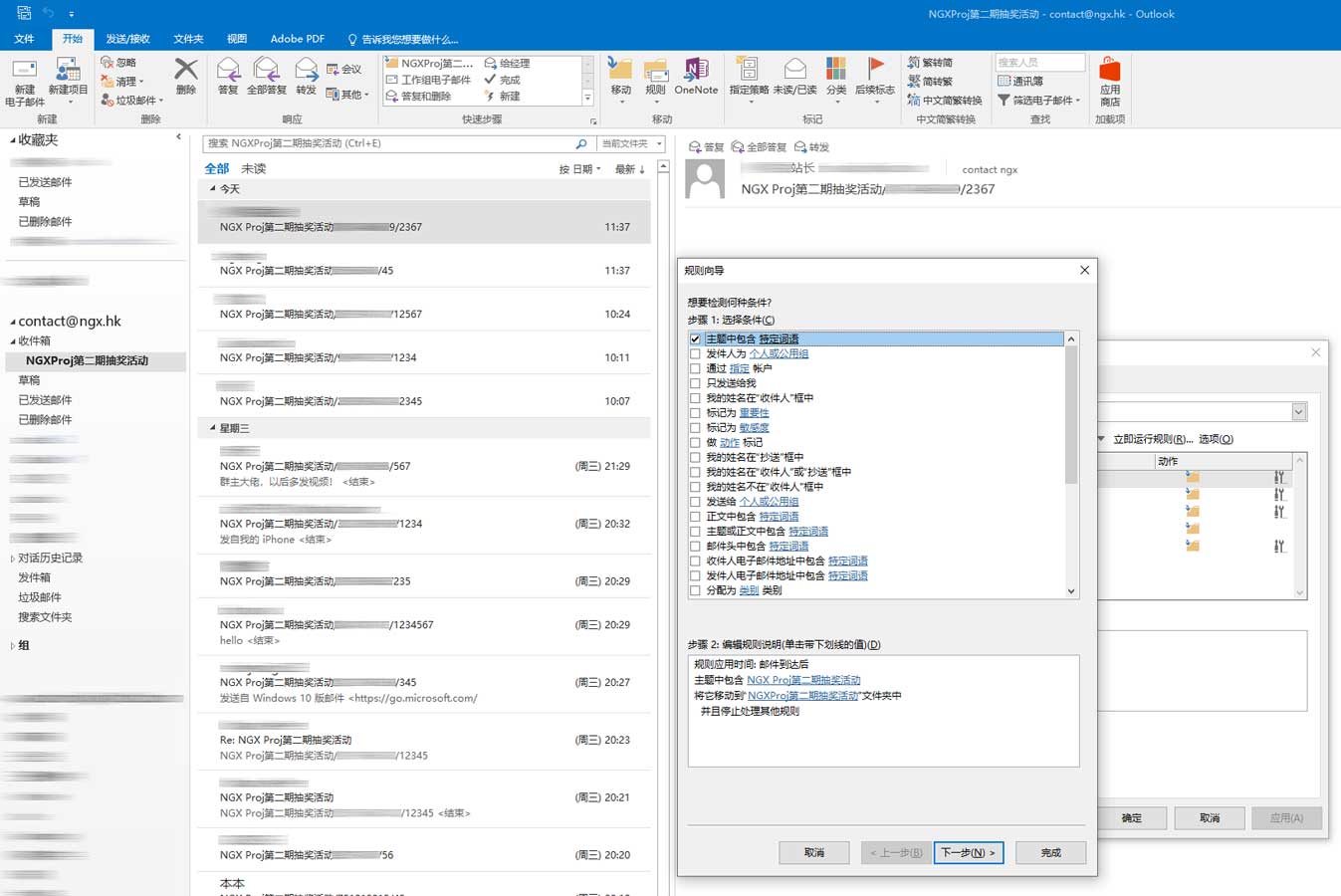
然后在邮件系统中新建一个文件夹用于存放报名邮件,还需要利用电子邮箱的自动规则功能识别邮件标题,并自动将报名邮件移动至该文件夹中。
因为我用的是office 365,所以这一切只需要在outlook中配置即可:
为了能通过脚本获取邮件,还需要开通邮箱系统的imap协议,以便通过imap协议登入邮件系统。
准备好之后即可开始编写脚本。
0x03 脚本
0x03.1 配置文件
首先需要准备配置文件,文件内容如下:
{
"email": {
"host": "outlook.office365.com",
"port": "993",
"username": "[email protected]",
"passwd": ""
},
"subj_prefix": "NGX Proj第二期抽奖活动",
"subj_count": 7
}
配置文件中包含电子邮箱的基本信息,因为我用的是office 365服务,所以信息如上。
还需要指定邮件标题的前缀,方便脚本中调用以便核查是否符合相关报名要求。最后是奖品类型的数量,这个数量的详情可以查看这次抽奖规则的文章。
0x03.2 定义基本信息
#!/usr/bin/python3 # -*- coding=utf-8 -*- import email import email.header import imaplib import os import sys from datetime import datetime # 定义目录 local_path = sys.path[0] # 邮箱账户信息配置文件 config_path = local_path + '/config.json' # 读取配置文件 r_conf = open(config_path, 'r') config_content = r_conf.read() r_conf.close() # 格式化配置文件 config_json = eval(config_content) # 邮件配置 imap_host = config_json['email']['host'] imap_port = config_json['email']['port'] imap_username = config_json['email']['username'] imap_passwd = config_json['email']['passwd'] subj_prefix = config_json['subj_prefix'] subj_count = config_json['subj_count'] # 通过IMAP登入邮箱服务器 comm = imaplib.IMAP4_SSL(imap_host, imap_port) comm.login(imap_username, imap_passwd) # 获取邮箱文件夹列表 # print(comm.list()) # 定义邮箱文件夹,list格式 mail_folder = ['INBOX/NGXProj&eyxOjGcfYr1ZVm07Uqg-']
脚本一开始是读取配置文件并将相关信息赋值给变量,方便后面的函数调用。
这个脚本需要用到email和imaplib这两个模块,imaplib主要实现与邮件服务器的imap通讯;而email则负责处理邮件内容。
首先调用imaplib模块登入邮件服务器,并获取邮箱文件夹列表,赋值给变量:mail_folder。如果邮箱文件夹的名称包含英文以外的文字,则会被编码,赋值的时候不需要解码,它输出什么就填写什么,如上所示。
0x03.3 获取邮件
电子邮件在文件夹中是有独一无二的编号的,而且这编号是自动增长的,根据收到邮件的先后顺序自行分配,就算其中的邮件被删除也不会变更其他在此文件夹内的邮件的编号。
所以获取邮件的第一步需要向邮件服务器索取这个邮件id列表,相关函数如下:
# 获取邮件uid
def get_uid_list(folder_name):
comm.select(folder_name)
response, uid_list = comm.uid('search', None, 'ALL')
uid_list = uid_list[0].decode().split(' ')
return uid_list
# 邮件服务器返还的内容如下
[b'1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 32 33 34 35 37']
# 该函数输出的内容如下
['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '32', '33', '34', '35', '37']
有了邮件id,就可以通过id和文件夹名称向服务器拉去邮件主体:
# 获取邮件内容与标题(subject)
def get_mail_data(folder_name, mail_uid):
comm.select(folder_name)
response, mail_data = comm.uid('fetch', mail_uid, '(RFC822)')
mail_data = email.message_from_string(mail_data[0][1].decode())
msg_subj = email.header.decode_header(mail_data['Subject'])
msg_subj = msg_subj[0][0].decode(msg_subj[0][1])
msg_sender = email.header.decode_header(mail_data['From'])
if len(msg_sender) == 1:
msg_sender = msg_sender[0][0].strip("'").split('<')[1][:-1]
elif len(msg_sender) == 2:
msg_sender = msg_sender[1][0].decode()[2:-1]
else:
msg_sender = msg_sender[2][0].decode()[2:-1]
return mail_data, msg_subj, msg_sender
一封邮件中包含的内容非常多,但我只需要邮件的内容、标题和发件人等信息。通过email.message_from_string函数可以很轻易地获取邮件不同部件的内容,然后加以处理即可得到我想需要的内容。
拉取邮件的时候需要注意的是,我的需求是拉取邮件的全部内容,在本地自行解析,这时候需要使用:
response, mail_data = comm.uid('fetch', mail_uid, '(RFC822)')
上面代码的意义为通过邮件的uid执行“fetch”命令,拉取该uid邮件的全部内容。
还有一种拉取邮件部分内容的方式:
IMAP4.fetch(message_set, message_parts)
通过这种方式可以减少数据的传输,比如需要拉取邮件的主题时,只需要拉取“Subject”即可,但在需要拉取多部份内容的情况下会导致请求次数过多,很久可能超过服务器的限制而导致脚本执行失败。
剩下的内容则是一些字符上的处理,没什么特别的。
0x03.4 文件存储与文件夹的建立
获取到邮件id列表后需要将最后的邮件id记录到一个临时文件中,当下次运行脚本时需要与之进行比对,以确认是否有新的邮件。
这个脚本本来是支持多个邮件文件夹的,为适配抽奖,我将大部分功能都删减了。但某些老旧的代码依然保留下来,下面的临时文件写入函数就是其中一个:
# 写入日志(N年前的代码片段,能用,但无心修改)
def write_log_to_file(folder, mail_uid):
if os.path.exists(log_file_path):
if os.path.getsize(log_file_path):
f = open(log_file_path, 'r')
f_dict = f.readline()
f_dict = eval(f_dict)
f_dict[folder] = mail_uid
f = open(log_file_path, 'w')
f.write(str(f_dict))
f.close()
else:
f_dict = dict()
f = open(log_file_path, 'w')
f_dict[folder] = mail_uid
f.write(str(f_dict))
f.close()
else:
f_dict = dict()
f = open(log_file_path, 'w')
f_dict[folder] = mail_uid
f.write(str(f_dict))
f.close()
它会将传入的文件夹名称与邮件uid组合成字典的形式并写入临时文件中,内容格式如下:
{'INBOX/NGXProj&eyxOjGcfYr1ZVm07Uqg-': '37'}
本来我是计划将邮件保存功能一并删除的,但最后还是保留下来,以便日后查验邮件内容,以下是邮件内容的函数:
# 邮件保存函数
def write_content_to_file(folder, mail_id, file_content):
mail_file_path = data_store_dir + folder + '/' + str(mail_id) + '.eml'
w_file = open(mail_file_path, 'w')
w_file.write(str(file_content))
w_file.close()
对数据保持一个简洁明了的文件夹结构是非常重要的,所以还针对数据存储路径做了简单规划:
# 获取日期
today_date = datetime.today().date()
today_date = str(today_date).replace('-', '_')
# 定义目录,用于存储邮件数据
data_store_dir = local_path + '/datastore/' + today_date + '/'
# 建立数据存储目录
for i_folder_name in mail_folder:
mail_content_dir = data_store_dir + i_folder_name
if os.path.exists(mail_content_dir):
if not os.path.exists(mail_content_dir):
os.mkdir(mail_content_dir)
else:
os.makedirs(mail_content_dir)
以上代码会生成以下文件与目录结构:
[root@web tmp]# tree -L 5 . ├── config.json ├── datastore │ └── 2018_11_10 │ └── INBOX │ └── NGXProj&eyxOjGcfYr1ZVm07Uqg- │ ├── 10.eml │ ├── 11.eml │ ├── 12.eml │ ├── 13.eml │ ├── 14.eml │ ├── 15.eml │ ├── 16.eml │ ├── 17.eml │ ├── 18.eml │ ├── 1.eml │ ├── 2.eml │ ├── 32.eml │ ├── 33.eml │ ├── 34.eml │ ├── 35.eml │ ├── 37.eml │ ├── 3.eml │ ├── 4.eml │ ├── 5.eml │ ├── 8.eml │ └── 9.eml ├── main.py ├── output.csv └── temp.log 4 directories, 25 files
0x03.5 uid的判断
拉取邮件前判断uid是否有效是非常重要的,可以避免重复性工作。以下是相关函数:
# 检查邮件uid是否已经存在
def check_last_mail_uid(folder, mail_uid):
temp_file_path = local_path + '/' + '.temp.log'
try:
temp_content = open(temp_file_path, 'r')
except FileNotFoundError:
return None, 0
else:
temp_content = temp_content.read()
temp_dict = eval(str(temp_content))
if folder in temp_dict:
mail_old_uid = temp_dict[folder]
if int(mail_uid) > int(mail_old_uid):
return True, mail_old_uid
else:
return False, 0
else:
return None, 0
这里分3中情况:
- 临时文件不存在:这说明从未进行过有效的邮件拉取动作,所以没有生成临时文件
- 有临时文件但文件夹名称不在字典内:这说明之前进行过有效的拉取动作,但未拉取过当前的目标目录
- 有临时文件且字典内有文件夹名称,且有与之对应的邮件id:这说明以前成功拉取过当前目标目录的邮件。
上面的函数会分别给三种不同的情况返还不同的内容,以便进行后续的工作。
0x03.6 邮件标题的格式化
在邮件源码内获取到邮件标题并不能直接使用,还需要对字符串进行处理:
# 格式化邮件标题,输出QQ号码与奖品列表
def format_subj(mail_subj):
mail_subj_list = mail_subj.split('/')
if mail_subj_list[0] == subj_prefix and len(mail_subj_list) == 3:
applicant_id = mail_subj_list[1]
subj_id_list = list(mail_subj_list[2])
return applicant_id, subj_id_list
else:
return False
我要求的邮件主题格式如下:
NGX Proj第二期抽奖活动/21999888/2367
首先以“/”为元素对字符串进行分割,形成列表,然后判断列表的第一个元素是否与配置文件中“subj_prefix”的值相匹配,且列表共有3个元素。如果是则进一步处理,否则返还False,告知程序跳过这个邮件的处理流程。
当邮件主题符合要求后,会将第三个元素列表化,与第二个元素一起返还。
0x03.7 csv
逗号分隔文档–csv的格式是最简单的,直接写入到文本文档即可,以下函数就是干这工作的:
# 输出csv文件
def csv_output(mail_sender, applicant_id, subj_id_list):
csv_output_front_part = mail_sender + ',' + applicant_id + ','
count_start = 1
while subj_count + 1 > count_start:
if str(count_start) in subj_id_list:
csv_output_front_part += 'True,'
else:
csv_output_front_part += 'False,'
count_start += 1
csv_file_path = local_path + '/output.csv'
if os.path.exists(csv_file_path):
csv_output_content = csv_output_front_part[:-1] + '\n'
else:
first_row_front_part = 'mail_sender' + ',' + 'applicant_id' + ','
count_start = 1
while subj_count + 1 > count_start:
first_row_front_part += str(count_start) + ','
count_start += 1
csv_output_content = first_row_front_part[:-1] + '\n' + csv_output_front_part[:-1] + '\n'
w_csv = open(csv_file_path, 'a')
w_csv.write(csv_output_content)
w_csv.close()
在写入之前需要组合每行的内容,通过遍历传入的奖品项目,然后将其转换为“True”和“False”即可。
接下来需要判断csv文件是否存在,如果不存在还需要组合首行内容,再和主要内容一起写入文件;如果文件存在则将主要内容写入即可。
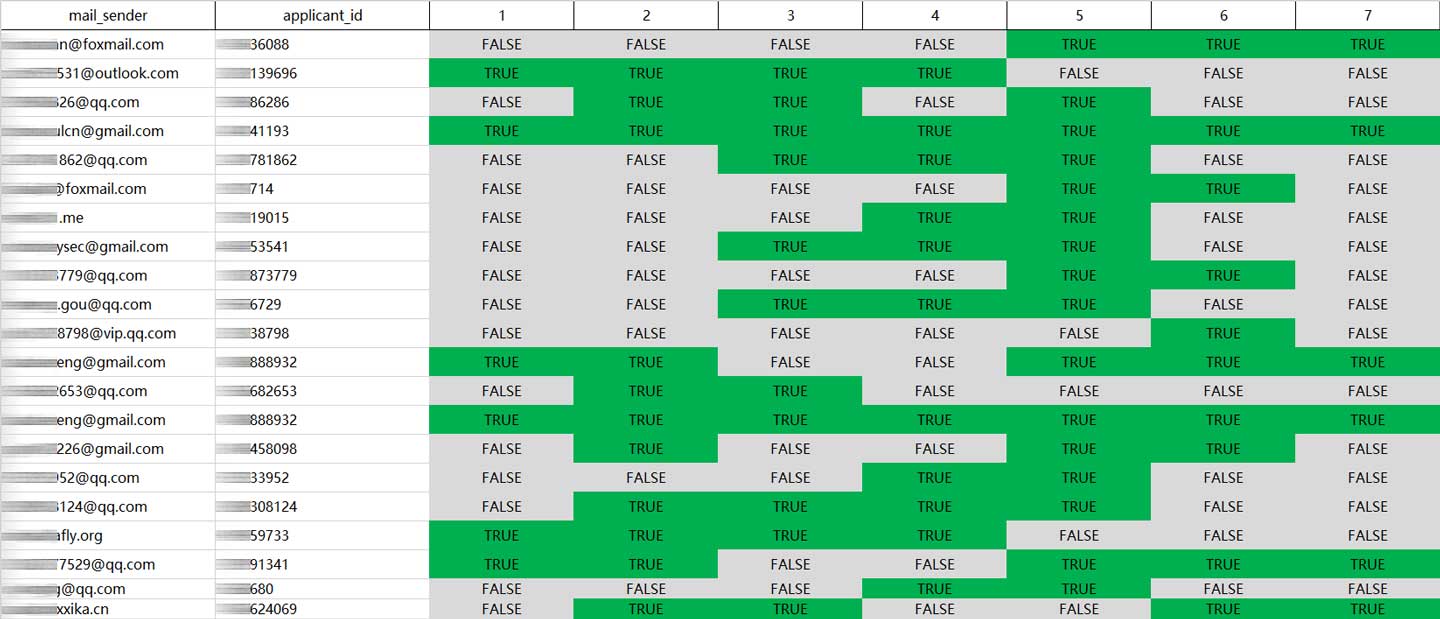
写入后的内容如下图:
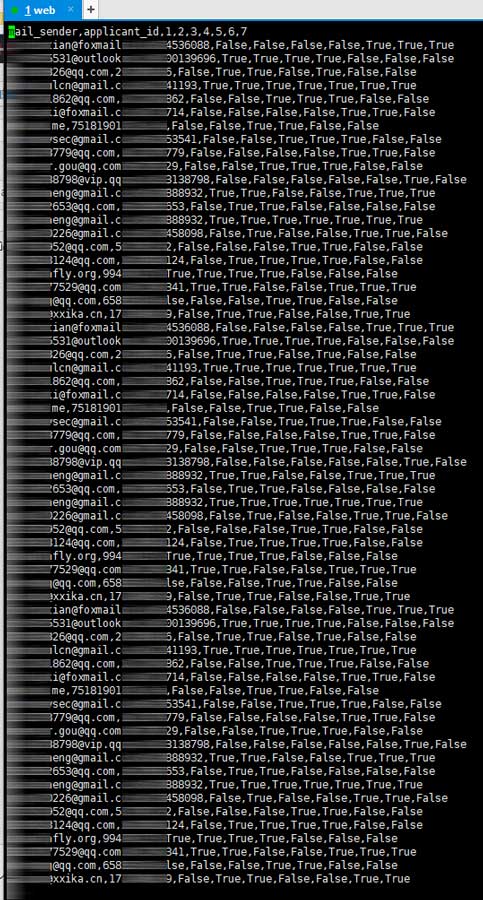
使用csv的一大好处是可以通过excel打开,打开后稍作修饰即可保存为excel的格式:
0x03.8 RUN
最后是run函数:
def run():
for i in mail_folder:
mail_uid_list = get_uid_list(i)
mail_uid_new = mail_uid_list[-1]
check_mail = check_last_mail_uid(i, mail_uid_new)
check_mail_uid = check_mail[0]
check_mail_value = check_mail[1]
# 该uid较temp文件中的大,说明有新邮件
if check_mail_uid:
mail_uid_old = int(check_mail_value)
while mail_uid_old < int(mail_uid_new):
mail_content = get_mail_data(i, str(mail_uid_old))
format_subj_tube = format_subj(mail_content[1])
if mail_content[0] is None or format_subj_tube is False:
write_log_to_file(i, mail_uid_old)
else:
write_content_to_file(i, mail_uid_old, mail_content[0])
csv_output(mail_content[2], format_subj_tube[0], format_subj_tube[1])
write_log_to_file(i, mail_uid_old)
mail_uid_old += 1
# 临时文件不存在或临时文件中没有相关邮件文件夹的key,说明从未下载过邮件
elif check_mail_uid is None:
for k in mail_uid_list:
mail_content = get_mail_data(i, k)
format_subj_tube = format_subj(mail_content[1])
if mail_content[0] is None or format_subj_tube is False:
write_log_to_file(i, k)
else:
write_content_to_file(i, k, mail_content[0])
csv_output(mail_content[2], format_subj_tube[0], format_subj_tube[1])
write_log_to_file(i, k)
# uid与临时文件中的值一致,说明无新邮件
else:
pass
逻辑比较清晰,但是功能实现可能不太理想,主要是调用上面所说的各类函数。
0x04 结语
经过半天的调试,终于完成基本功能,估计以后的抽奖活动也会采用这种报名方式。在后续可能会增加实时展示功能,通过该功能可以将报名情况写入数据库,在前端显示。
生命在于折腾,其实我发现wordpress是由相关功能的插件的,但我就是不用!
通过我私有的gitlab可以找到最新的代码,还可以查看更新记录噢:






















