
0x01 前言
我是用Cachet系统对外展示我系统的一些信息与状态,之前写过一篇文章,通过python脚本更新它的metrics数据,展示效果如下:

以下是相关文章:
近期有位群友想实现Cachet与zabbix之间的互动,获取zabbix中的告警信息并更新Cachet中的系统状态与添加事件记录。
我原本有个小脚本,但实现起来非常繁琐,所以我重新整理逻辑并花一天事件编写一个新的脚本实现以上需求。虽然实现了基本需求,但依旧繁琐且事件记录过于详细,容易泄露敏感数据;另外逻辑也有待优化。
0x02 思路
我利用zabbix的告警提醒功能调用外部的脚本,并向该脚本发送定制的告警内容。然后脚本自动处理告警信息,最后更新Cachet中的数据。
但在Cachet中的部件名称不一定为zabbix中的设备名,另外因为Cachet中的事件记录只支持获取全部或通过事件id进行获取,结合这两个原因,还需要建立一个临时文件,用于存储zabbix hostname、zabbix事件id与Cachet事件id的对应关系。
目前脚本仅支持固定得事件记录内容,而且当zabbix异常恢复后会更新事件记录得内容,但这会将异常信息删掉。在实际应用中这并不是很好的操作,所以计划在下一个版本修改为可自定义的格式并保留告警信息。
因为有可能会出现单一zabbix监控目标出现多个告警情况,所以还得对Cachet临时文件做出增删查的基本功能,这部分异常复杂,下个版本也需要更新。
0x03 部署
首先需要准备配置文件,配置文件名为“cachethq_status_updater_conf.json”,内容如下:
{
"config_main": {
"cachethq_url": "https://status.ngx.hk/api/v1/",
"cachethq_api_key": "qazxfjhdxfkjhget"
},
"host": {
"t620-idrac": 22,
"cn1.ngx.hk": 16,
"cn2.ngx.hk": 1,
"hk1.ngx.hk": 2,
"pub-ngx.t.com": 4,
"gitlab.t.com": 5,
"web.t.com": 6,
"es6-node1.t.com": 7,
"es6-node2.t.com": 7,
"es6-node3.t.com": 7,
"logstash6-node1.t.com": 7
}
}
config_main中记录着Cachet的API地址与API key,这部分内容请留意以下文章:
最重要的是host中的字典,字典中的key为zabbix中的hostname,如果在zabbix host设置中为监控点设置了“Visible name”,则key应为“Visible name”的值:
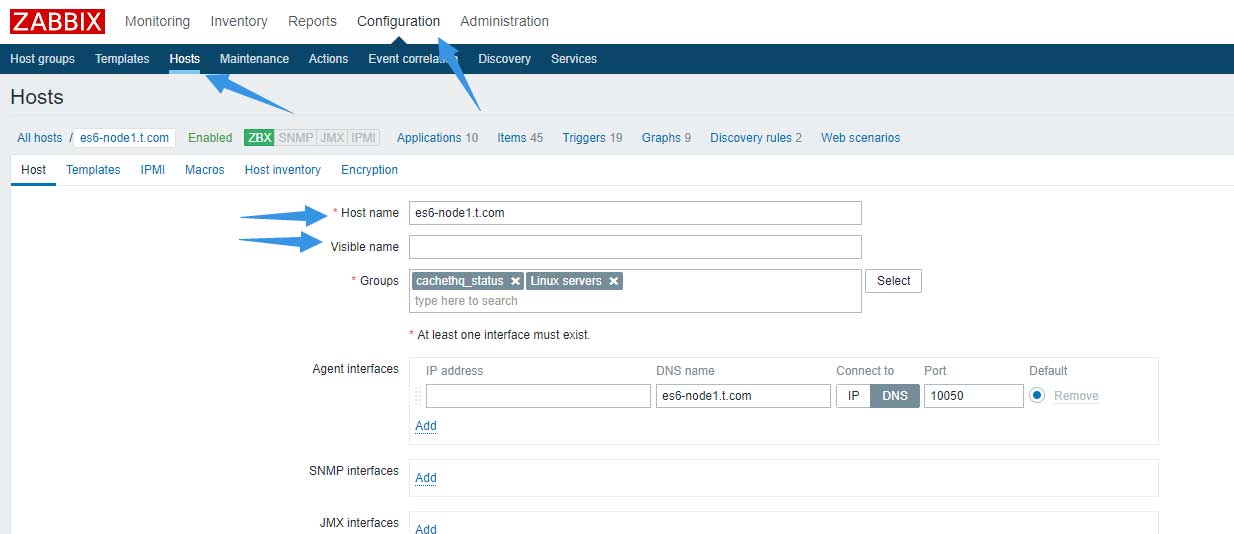
而value是Cachet中部件所对应的的id:
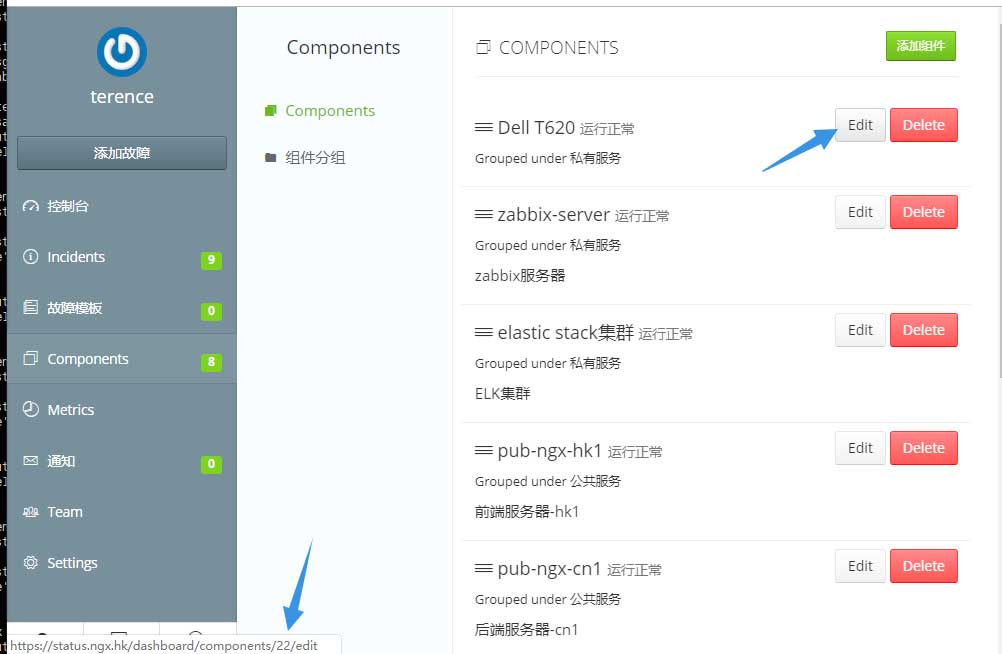
0x03.1 zabbix host groups
然后还需要给zabbix配置告警动作,首先到configuration –> host groups中添加一个名为cachethq_status的主机组:
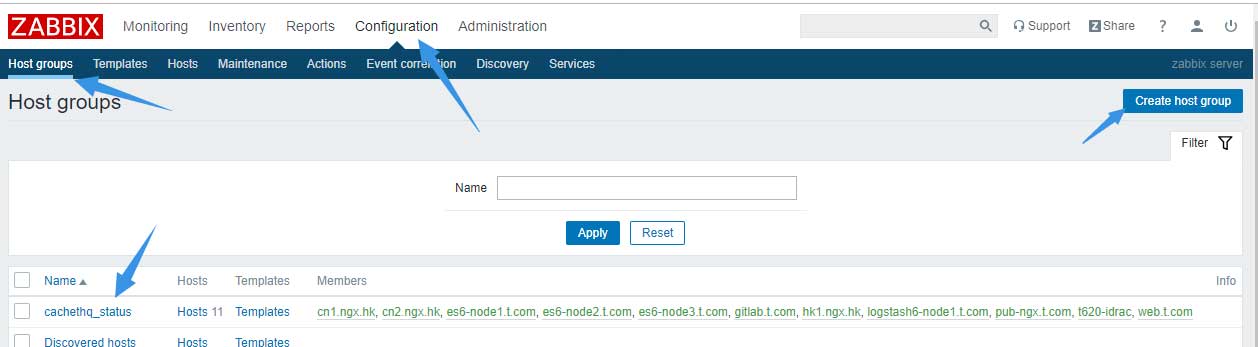
0x03.2 zabbix Media types
紧接着新建Media types:
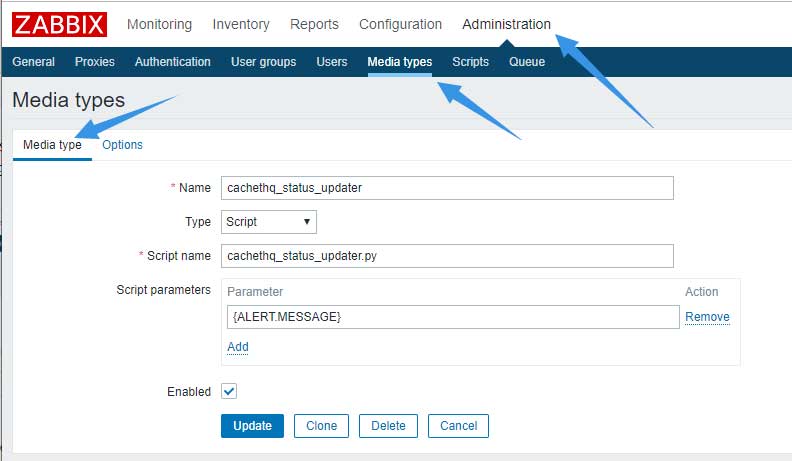
相关内容如下:
# Name
cachethq_status_updater
# Type
Script
# Script name
cachethq_status_updater.py
# Script parameters
{ALERT.MESSAGE}
Options标签中的内容保持默认即可。
0x03.3 zabbix actions
最后到configuration –> actions中添加一个新的action:
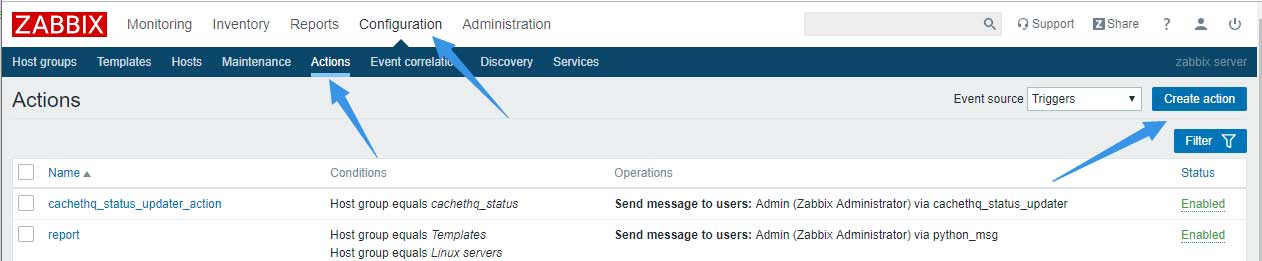
在action标签中配置一个动作名称,并在condition中选择主机组等于cachethq_status,选择完成后记住单击“Add”才算完成condition的添加;勾选Enable,然后单击Operations标签:
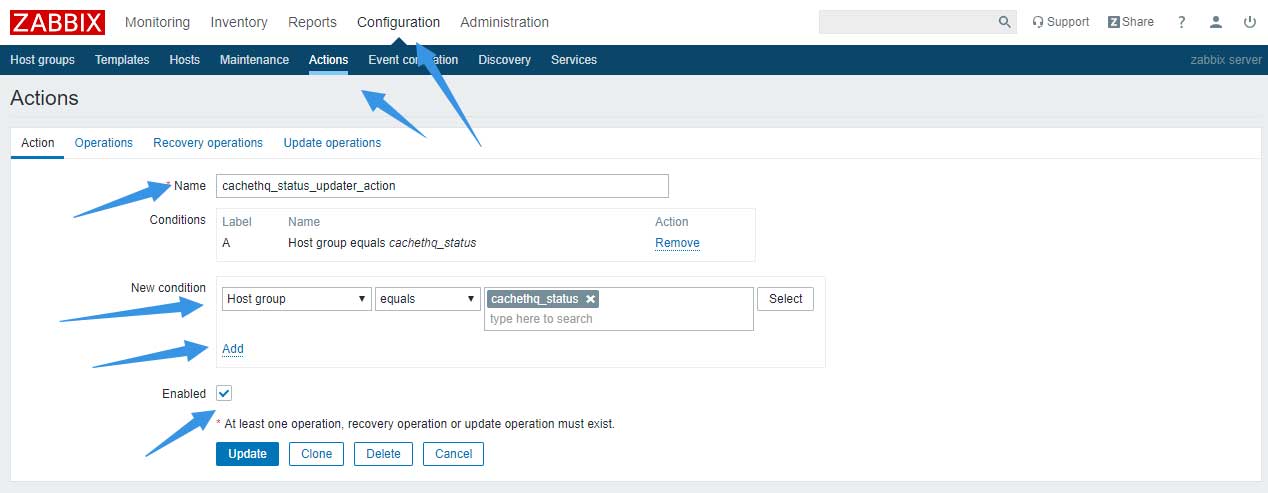
配置内容如下:
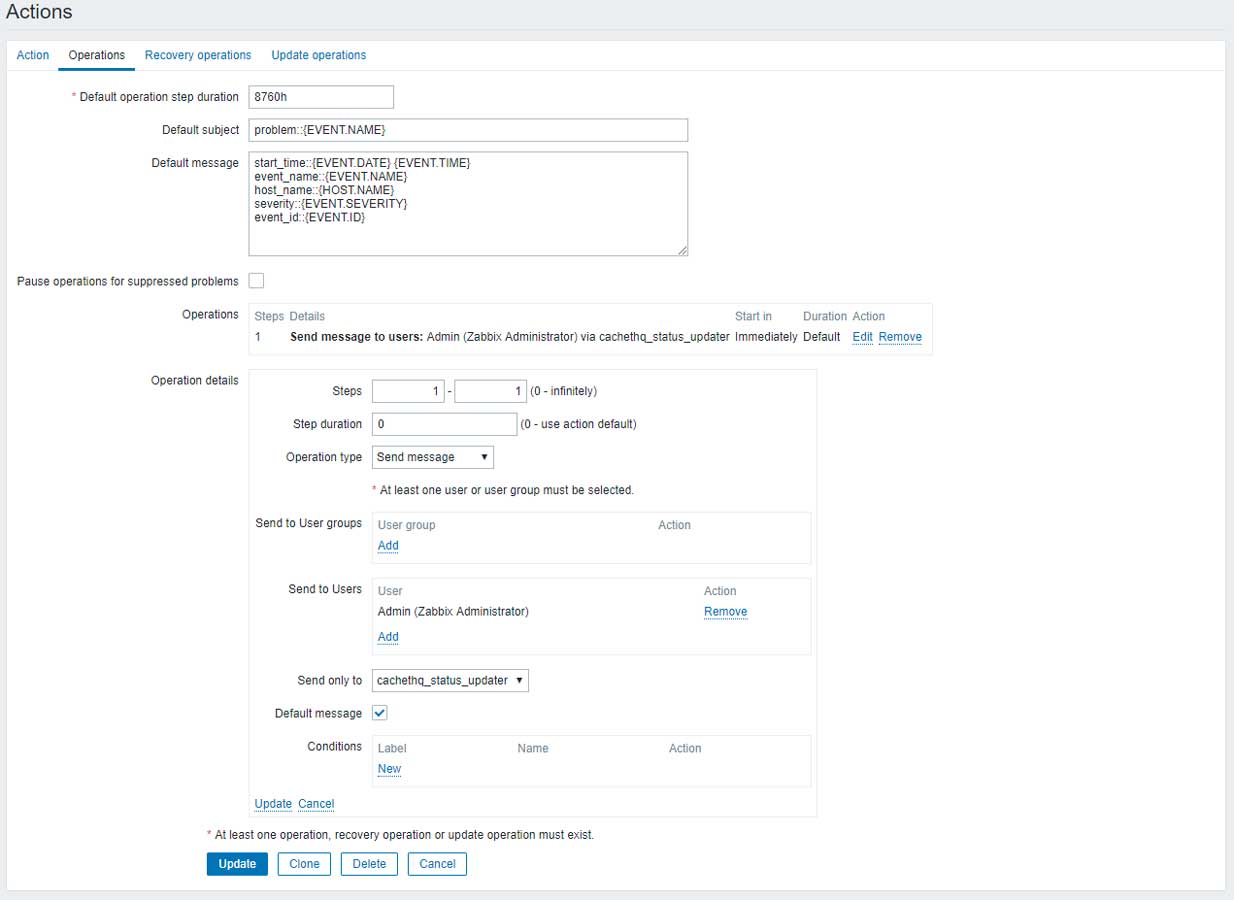
其中”Default operation step duration”请添加尽可能大的数,因为我们不需要重复提醒;”Operation details”中的”Steps”请填写1-1,只通知一次即可;”“选择上面建立的Media type即可。
Operations标签中”Default subject”与”Default message”的内容如下:
problem::{EVENT.NAME}
start_time::{EVENT.DATE} {EVENT.TIME}
event_name::{EVENT.NAME}
host_name::{HOST.NAME}
severity::{EVENT.SEVERITY}
event_id::{EVENT.ID}
请勿更改以上内容与格式。
Recovery operations标签中的配置如下:
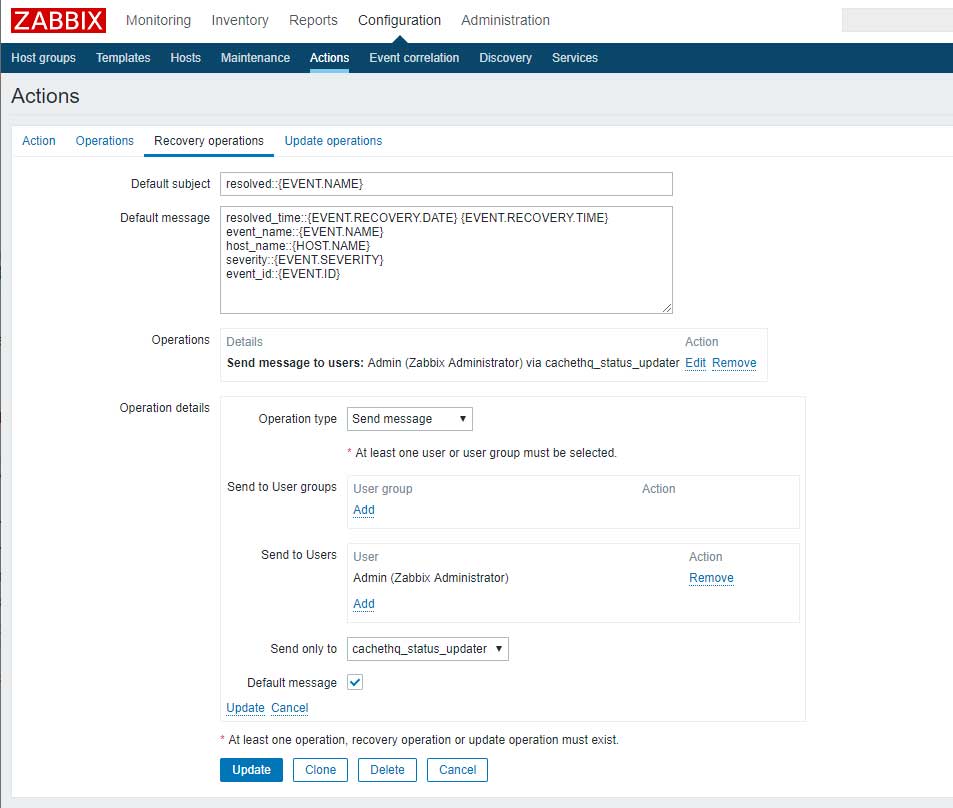
“Operation details”中的”“选择上面建立的Media type即可。
相关内容如下:
resolved::{EVENT.NAME}
resolved_time::{EVENT.RECOVERY.DATE} {EVENT.RECOVERY.TIME}
event_name::{EVENT.NAME}
host_name::{HOST.NAME}
severity::{EVENT.SEVERITY}
event_id::{EVENT.ID}
0x03.4 zabbix 脚本
clone源码之前需要修改zabbix server的配置文件:
# 编辑文件 [root@web ~]# vim /usr/local/zabbix/etc/zabbix_server.conf # 修改该字段 AlertScriptsPath=/usr/local/shell/zabbix
AlertScriptsPath的值为一个目录,其中的脚本的所有这需要修改为zabbix的用户与用户组并赋予可执行权限,具体路径请根据实际情况进行选择。
完成上面的配置后即可从我的gitlab中clone源码到本地并将以下文件放置到AlertScriptsPath的目录中:
[root@web ~]# ll /usr/local/shell/zabbix/ total 20 -rw-r--r-- 2 zabbix zabbix 425 Nov 8 21:27 cachethq_status_updater_conf.json -rwxr-xr-x 2 zabbix zabbix 4941 Nov 8 21:15 cachethq_status_updater.py
0x03.5 测试
完成上述操作后需要重启zabbix server,随后即可通过调整zabbix中的阈值进行测试。最简单的测试方式是停止监控点的zabbix-agent,待出现告警后,zabbix server会自动调用脚本,更新Cachet中的数据:
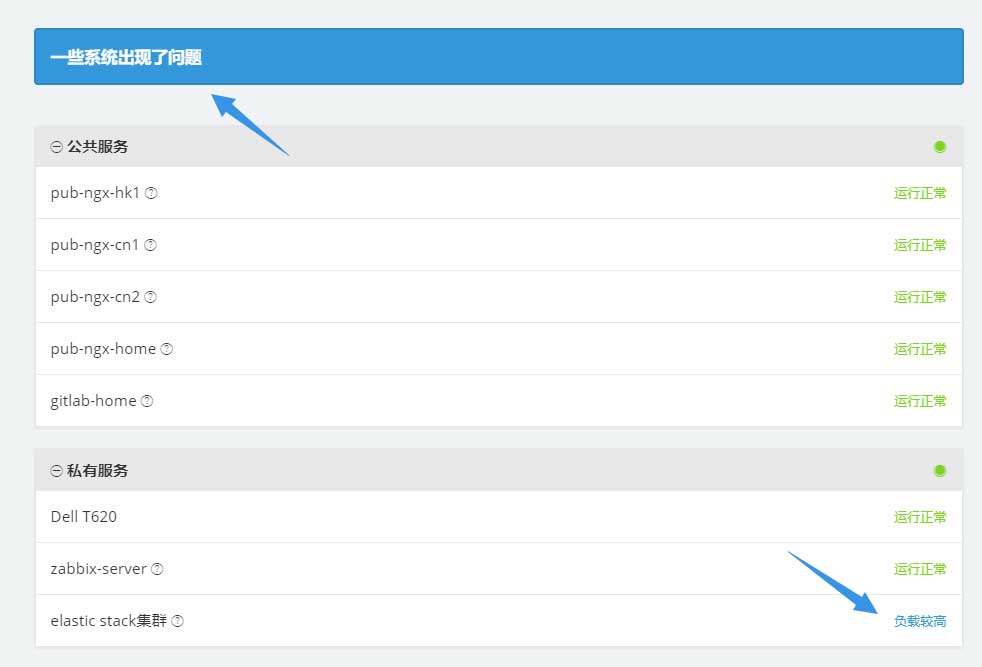
事件记录如下:
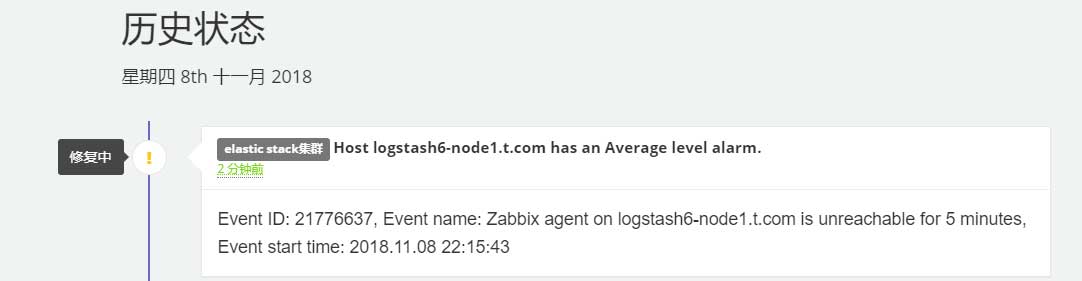
重新启动zabbix agent后即可恢复正常。
0x04 源码
第一行需要定义python3的路径,紧接着接受传入数据,然后读取配置文件,最后是定义临时文件路径:
#!/usr/bin/python3 import sys import requests import json # 接收传入内容 msg = sys.argv[1] config_content = open(sys.path[0] + '/cachethq_status_updater_conf.json') config_dict = json.load(config_content) cachethq_url = config_dict['config_main']['cachethq_url'] cachethq_api_key = config_dict['config_main']['cachethq_api_key'] cachethq_host_dict = config_dict['host'] temp_file_path = sys.path[0] + '/cachethq_status_updater.temp'
针对传入的内容,转换为字典格式:
def zabbix_msg_handler():
zbx_msg_list = msg.split('\n')
zbx_msg_dict = dict()
for i in zbx_msg_list:
i_list = i.split('::')
zbx_msg_dict[i_list[0]] = i_list[1].strip('\r')
return zbx_msg_dict
传入内容如下:
# 告警内容 start_time::2018.11.08 11:27:32 event_name::Inlet Temp warning host_name::t620-idrac severity::Warning event_id:::21759621 # 恢复内容 resolved_time::2018.11.08 11:49:32 event_name::Inlet Temp warning host_name::t620-idrac severity::Warning event_id::21760075
转换后的内容如下:
# 告警内容
{'severity': 'Warning', 'host_name': 't620-idrac', 'event_id': ':21739925', 'start_time': '2018.11.07 23:03:02', 'event_name': 'Inlet Temp warning'}
# 恢复内容
{'event_name': 'Inlet Temp warning', 'resolved_time': '2018.11.08 11:35:33', 'host_name': 't620-idrac', 'severity': 'Warning', 'event_id': '21759715'}
以下是创建事件记录并修改部件状态的函数:
def create_incidents(api_token, inc_name, inc_msg, inc_status, inc_visible, comp_id, comp_status):
req_url = cachethq_url + 'incidents'
payload = {
"name": inc_name,
"message": inc_msg,
"status": inc_status,
"visible": inc_visible,
"component_id": comp_id,
"component_status": comp_status
}
headers = {'X-Cachet-Token': api_token}
req_run = requests.request('POST', req_url, data=payload, headers=headers)
req_content = json.loads(req_run.text)
inc_id = req_content['data']['id']
return inc_id
以下是修改事件记录并修改部件状态的函数:
def update_incidents(api_token, inc_id, inc_name, inc_msg, inc_status, inc_visible, com_id, comp_status):
req_url = cachethq_url + 'incidents/' + str(inc_id)
payload = {
"name": inc_name,
"message": inc_msg,
"status": inc_status,
"visible": inc_visible,
"component_id": com_id,
"component_status": comp_status
}
headers = {'X-Cachet-Token': api_token}
req_run = requests.request('PUT', req_url, data=payload, headers=headers)
req_content = json.loads(req_run.text)
return req_content
创建与修改都需要通过”X-Cachet-Token”这个header传递api token,这两部分的API可以通过以下地址找到相关信息:
接下来是整个脚本逻辑最混乱的一个函数:
def r_w_d_temp_file(act_type, host_name, event_id, incident_id):
try:
r = open(temp_file_path, 'r')
except FileNotFoundError:
r = open(temp_file_path, 'w')
r.write('{}')
r.close()
temp_content = dict()
else:
temp_content = json.loads(r.read())
r.close()
if act_type == 'r':
try:
incident_id = temp_content[host_name][event_id]
except KeyError:
return False
else:
event_count = len(temp_content[host_name])
return incident_id, event_count
elif act_type == 'd':
del temp_content[host_name][event_id]
r = open(temp_file_path, 'w')
r.write(str(json.dumps(temp_content)))
r.close()
return None
elif act_type == 'w':
if host_name in temp_content:
temp_content[host_name][event_id] = incident_id
else:
id_dict = dict()
id_dict[event_id] = incident_id
temp_content[host_name] = id_dict
r = open(temp_file_path, 'w')
r.write(str(json.dumps(temp_content)))
r.close()
return None
else:
pass
以上函数主要实现对临时文件的增删查功能,首先通过try尝试读取临时文件,如果文件不存在则创建文件并填入一个空字典,以免首次运行脚本时报错;如果文件存在则读取并格式化为字典。
接下来的逻辑如下:
- “act_type”为”r”:查询模式,尝试读取”event_id”的value,如果值不存在的返还False,说明该值不存在,需要建立。我的设想是只有在zabbix出现告警时才会使用查询模式,但后来发现单一监控点可能会出现多个告警,这时候监控点告警恢复时也需要调用该模式。所以增加了event_count值在event_id存在时一起回传;
- “act_type”为”d”:删除模式,当zabbix异常恢复后,从字典中删除对应的key。我的设想是异常恢复肯定在异常恢复之后,所以相关的event_id肯定在字典中,此时只需要删除即可,不需要其他操作;
- “act_type”为”w”:写入模式,我的设想是只有在zabbix出现异常时才会写入,所以这里会有两种情况:
- 监控点从未出现过:此时需要建立一个新的监控点字典并与现有的字典合并;
- 监控点已出现过:此时只需要增加event_id及其对应的value即可。
最后的pass只是想让逻辑更完整而已,没啥用。
最后是run函数:
def run():
msg_dict = zabbix_msg_handler()
if 'start_time' in msg_dict:
incidents_name = 'Host ' + msg_dict['host_name'] + ' has an ' + msg_dict['severity'] + ' level alarm.'
incidents_msg = 'Event ID: ' + str(msg_dict['event_id']) + \
', Event name: ' + msg_dict['event_name'] + \
', Event start time: ' + msg_dict['start_time']
if msg_dict['severity'] is 'Not classified' or 'Information':
component_status = 2
elif msg_dict['severity'] is 'Warning' or 'Average':
component_status = 3
elif msg_dict['severity'] is 'High' or 'Disaster':
component_status = 4
else:
component_status = 1
incidents_id = create_incidents(cachethq_api_key, incidents_name, incidents_msg, 2, 1,
cachethq_host_dict[msg_dict['host_name']], component_status)
r_w_d_temp_file('w', msg_dict['host_name'], msg_dict['event_id'], incidents_id)
elif 'resolved_time' in msg_dict:
incidents_name = 'The alarm of the ' + msg_dict['severity'] + ' level of host ' + msg_dict[
'host_name'] + ' has been released.'
incidents_msg = 'Event ID: ' + str(msg_dict['event_id']) + \
', Event name: ' + msg_dict['event_name'] + \
', Event resolved time: ' + msg_dict['resolved_time']
incidents_id = r_w_d_temp_file('r', msg_dict['host_name'], msg_dict['event_id'], 0)[0]
update_incidents(cachethq_api_key, incidents_id, incidents_name, incidents_msg, 4, 1,
cachethq_host_dict[msg_dict['host_name']], 1)
r_w_d_temp_file('d', msg_dict['host_name'], msg_dict['event_id'], 0)
else:
pass
这部分内容也是一团糟,只是把功能实现而已。
首先判断传入的内容是发生异常还是异常恢复,然后根据内容的不容组合事件记录的内容,最后分别调用事件记录的创建与更新函数。
这部分有个明显的缺陷:内容过于详细,极其容易造成信息泄露。
0x05 结语
脚本尚处于dev阶段,目前可以通过以下地址找到完整的脚本:
因为这个脚本是被动的脚本,和更新Metrics的脚本有本质上的区别,所以两者不会合并。
这脚本是在半天内临时编写的,相关功能与逻辑尚不完善,开发工作会在接下来的一个月继续,有需要的朋友可持续关注我的gitlab。还可以通过以下地址查看我私有服务的状态:






















