
0x01 前言
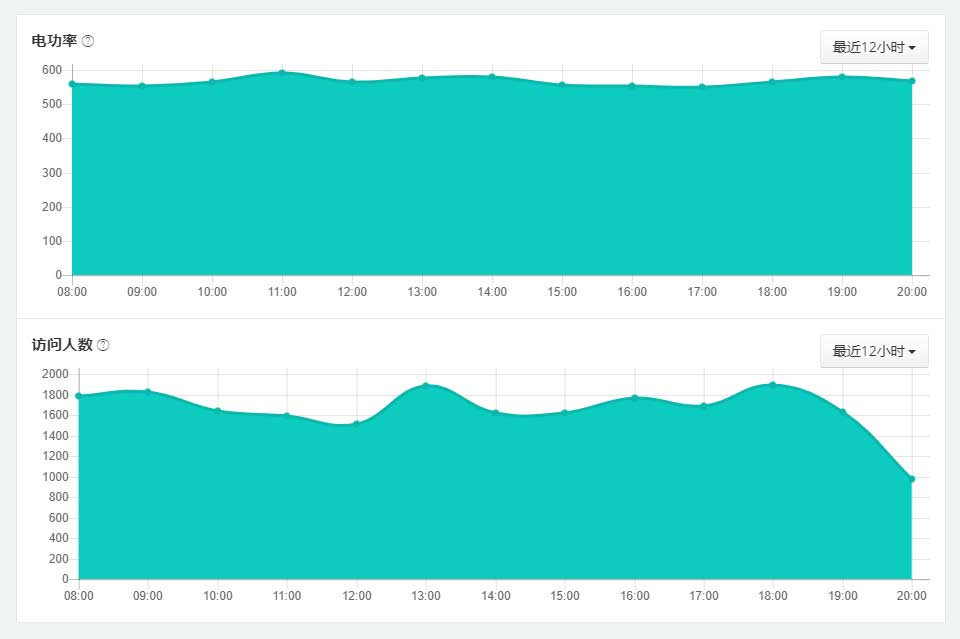
经常有人问我家里服务器的功率是多少,我网站的访问量是多少,在经过一番斗争后我决定将这些数据通过status pages展示出来。
在前两周我配置好了一款名为Cachet开源的status pages服务(NGX Services Status Page),配置过程请参考以下文章:
这次我还是使用python脚本调用各个系统的API,然后将数据填充到Cachet中,最终以图表的形式展示出来:
0x02 准备
首先,需要安装上面的文章配置好Cachet,然后登入到控制台,到METRICS标签中添加图表:

先配置电功率的图表,在配置过程中需要注意“图表计算方法”这个选项,我的计划是每分钟从zabbix中取数据,然后写入Cachet,所以这里需要选择average(平均数);然后配置nginx的访问次数,而这里则需要选择sum(总和):

上图中的“Suffix”为单位,可根据实际情况进行填写。
填写完所有内容后即可单击“ADD”以完成图表的创建。

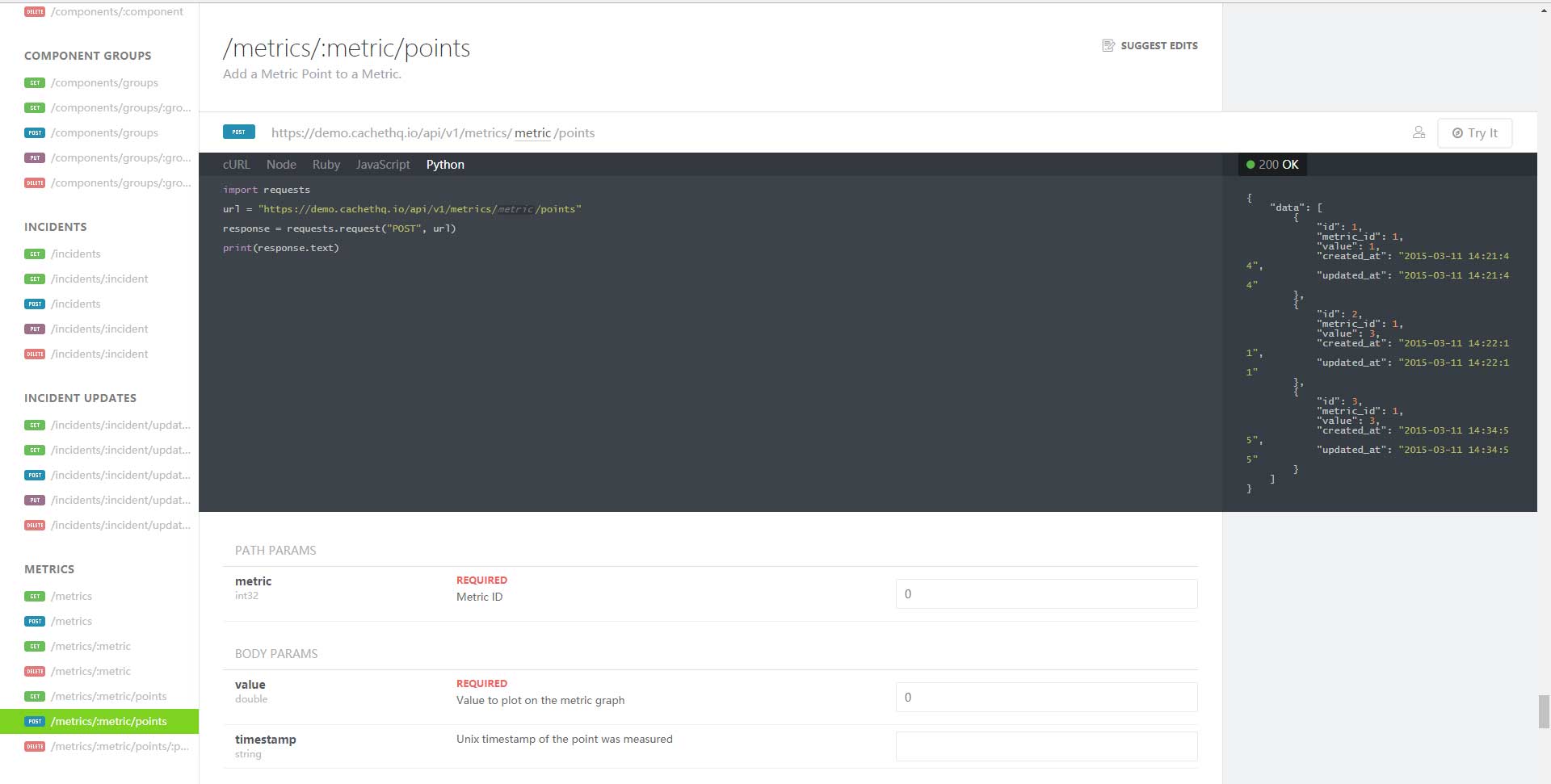
在开始编写脚本之前需要Cachet相关的API信息,所有的API可以在以下地址中找到:
因为需要在图表中插入数据,所以在这里我们需要用到以下API:
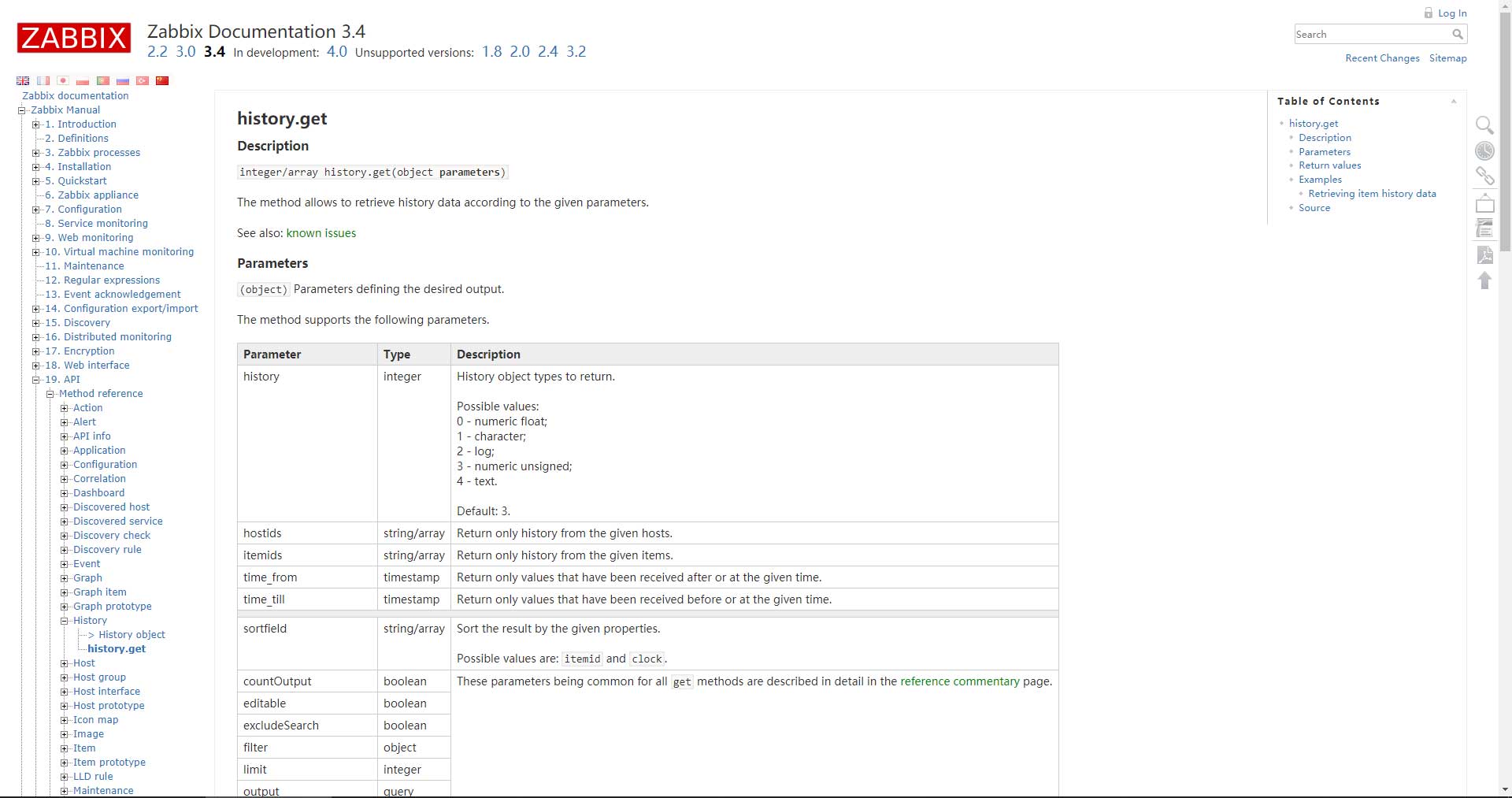
还需要在zabbix中取数据,所以需要在以下地址中寻找zabbix的API信息:
而我的nginx日志是在ELK中分析的,所以还需要找到elasticsearch相关的信息:
这部分的内容比较复杂,需要有一个系统的学习或初步的认识才能理解,所以这里不多做讲解。
0x03 脚本
首先需要定义三个服务的API地址:
zbx_api_url = 'http://zabbix.t.com/api_jsonrpc.php' es6_api_url = 'http://es6-node1.t.com:9200/' cachethq_url = 'https://status.ngx.hk/api/v1/'
0x03.1 时间戳
我这个脚本会每分钟执行一次,而我希望将这些数据插入Cachet中的整分钟点钟(这句话有点难理解),例如:
- 19:01:00
- 19:02:00
- 19:03:00
- 19:04:00
与此同时,Cachet的API仅接受时间戳格式的时间表达,所以,我需要预先处理下时间:
def get_datetime():
datetime_now = datetime.today().strftime("%Y-%m-%d %H:%M:00")
datetime_now = datetime.strptime(datetime_now, '%Y-%m-%d %H:%M:%S')
datetime_old = datetime_now - timedelta(minutes=1)
timestamp_now = datetime_now.timestamp()
timestamp_now = int(timestamp_now * 1000)
timestamp_old = datetime_old.timestamp()
timestamp_old = int(timestamp_old * 1000)
output_dict = dict()
output_dict['timestamp_now'] = str(timestamp_now)
output_dict['timestamp_old'] = str(timestamp_old)
return output_dict
先定义一个函数,获取当前的时间,但秒数我强制修改为“00”,然后再用strptime格式化。
因为需要在elasticsearch中搜索前一分钟内的访问量,所以还需要算出前一分钟的时间,用变量名datetime_old表示。
最后输出以下格式的字典:
{'timestamp_old': '1529933400000', 'timestamp_now': '1529933460000'}
0x03.2 zabbix
zabbix的API调用需要通过用户名和密码获取一个token,用完之后还需要登出以销毁该token,所以会有以下两个函数,分别实现登入和登出:
def zbx_login(zbx_username, zbx_passwd, zbx_id):
payload = {
"jsonrpc": "2.0",
"method": "user.login",
"params": {
"user": zbx_username,
"password": zbx_passwd
},
"id": zbx_id,
}
headers = {'content-type': 'application/json'}
req_run = requests.post(zbx_api_url, data=json.dumps(payload), headers=headers)
req_content = json.loads(req_run.text)
return req_content
def zbx_logout(zbx_login_id, zbx_login_token):
payload = {
"jsonrpc": "2.0",
"method": "user.logout",
"params": [],
"id": zbx_login_id,
"auth": zbx_login_token
}
headers = {'content-type': 'application/json'}
req_run = requests.post(zbx_api_url, data=json.dumps(payload), headers=headers)
req_content = json.loads(req_run.text)
return req_content
在登入函数中的payload有个id值,这里用时间戳填充,其实这是不严谨的,应该用UUID填充,这样才能保证该token与id对应的唯一性,但我的应用环境中要求不高,所以直接用时间戳填充。
登入和登出函数的输出内容如下:
#zbx_login
{'jsonrpc': '2.0', 'id': '1529934000000', 'result': 'e925d67c6fc019447db9e63eb1d27a21'}
#zbx_logout
{'jsonrpc': '2.0', 'id': '1529934000000', 'result': True}
取得zabbix token之后就可以调用history.get这个API获取最新的一条数据了:
def get_zbx_item_value(zbx_token, zbx_item_id):
payload = {
"jsonrpc": "2.0",
"method": "history.get",
"params": {
"output": "extend",
"history": 0,
"itemids": zbx_item_id,
"sortfield": "clock",
"sortorder": "DESC",
"limit": 1
},
"auth": zbx_token,
"id": 1
}
headers = {'content-type': 'application/json'}
req_run = requests.post(zbx_api_url, data=json.dumps(payload), headers=headers)
req_content = json.loads(req_run.text)
req_value = req_content['result'][0]['value']
return str(req_value)
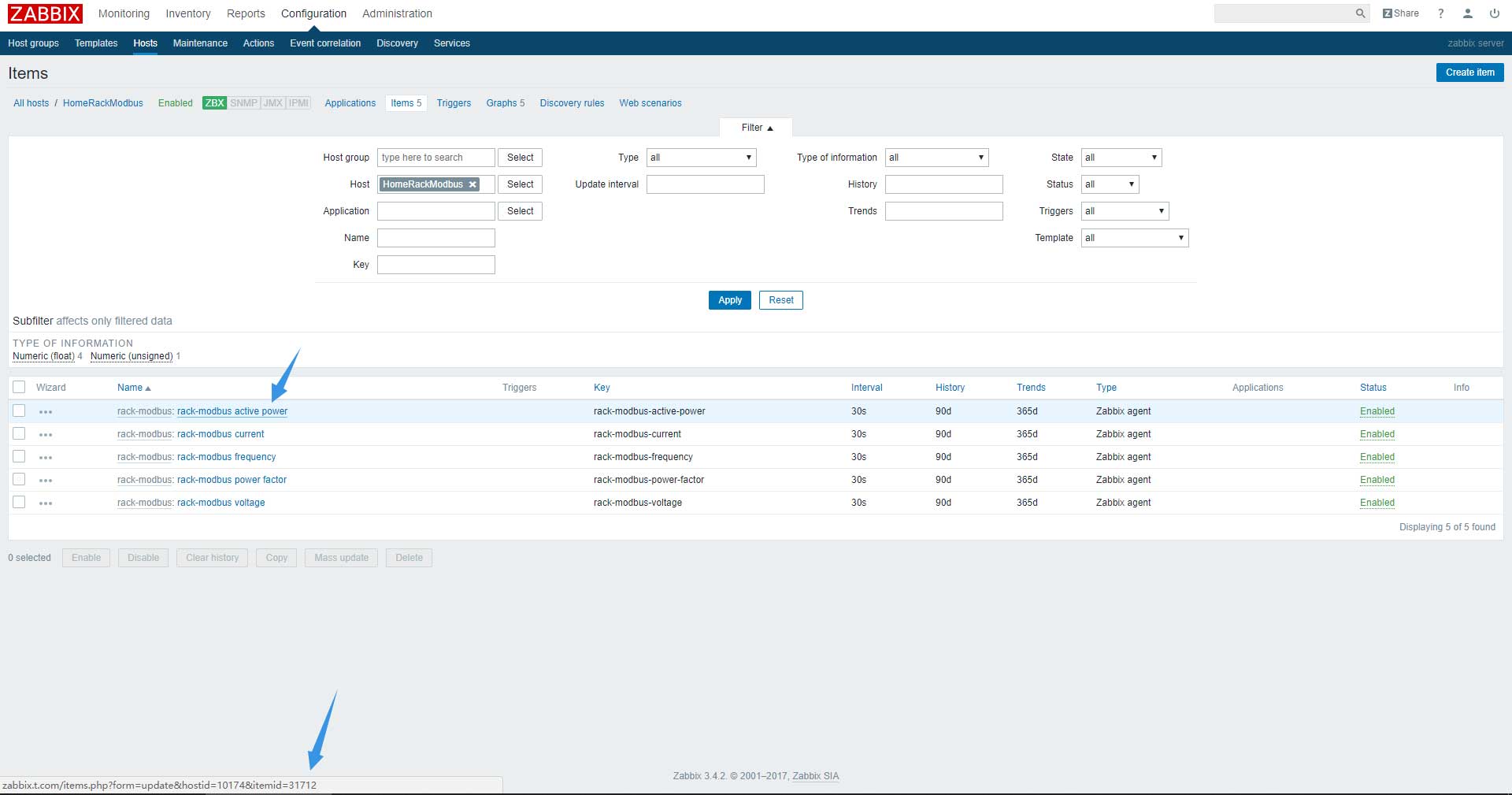
因为在zabbix中,item的id是唯一的,所以只需要找到相应的item,就可以找到相应的id:
然后利用zabbix token与item id一起调用该函数,返还的结果如下:
553.8000
其实返还的实际内容是json格式的,只是经过数据提取后,直接返还了实际的数值:
{
'id': 1,
'result': [
{
'ns': '598647172',
'clock': '1529934932',
'value': '593.8000',
'itemid': '31712'
}
],
'jsonrpc': '2.0'
}
0x03.3 elasticsearch
elasticsearch的数据统计比较简单,因为我只想知道一分钟内的访问量有多少,那么我只需要计算出这一分钟内elasticsearch接收到多少条日志就可以了,至于请求的内容是图片、js还是css我并不关心,所以payload的json如下:
{
"size": 0,
"_source": {
"excludes": []
},
"aggs": {},
"stored_fields": [
"@timestamp"
],
"query": {
"bool": {
"must": [
{
"match_all": {}
},
{
"range": {
"@timestamp": {
"gte": es_gte,
"lte": es_lte,
"format": "epoch_millis"
}
}
}
]
}
}
}
另外,在请求的header中必须将payload设置为json:
headers = {'content-type': 'application/json'}
完整的函数如下:
def get_number_of_visits(es_index_name, es_gte, es_lte):
payload = {
"size": 0,
"_source": {
"excludes": []
},
"aggs": {},
"stored_fields": [
"@timestamp"
],
"query": {
"bool": {
"must": [
{
"match_all": {}
},
{
"range": {
"@timestamp": {
"gte": es_gte,
"lte": es_lte,
"format": "epoch_millis"
}
}
}
]
}
}
}
headers = {'content-type': 'application/json'}
req_run = requests.post(es6_api_url + es_index_name + '/_search', data=json.dumps(payload), headers=headers)
req_content = json.loads(req_run.text)
req_value = req_content['hits']['total']
return str(req_value)
和zabbix获取数值的函数一样,最终输出的结果也是经过处理的:
118
而原始的返还内容如下:
{
'took': 2,
'_shards': {
'skipped': 0,
'total': 5,
'failed': 0,
'successful': 5
},
'hits': {
'hits': [],
'total': 118,
'max_score': 0.0
},
'timed_out': False
}
0x03.4 Cachet
获取到所需要的数据后,接下来需要将数据填充到Cachet中,直接调用API即可:
def cachethq_metrics_add_point(api_token, metric_id, metric_value, metric_timestamp):
req_url = cachethq_url + 'metrics/' + str(metric_id) + '/points'
payload = {
"value": metric_value,
"timestamp": metric_timestamp
}
headers = {'X-Cachet-Token': api_token}
req_run = requests.request('POST', req_url, data=payload, headers=headers)
req_content = json.loads(req_run.text)
return req_content
Cachet的API调用也需要验证身份,不过不需要使用用户名和密码,而是通过在header中添加“X-Cachet-Token”的token值即可,而这个token可以在控制台中点击头像,在个人信息配置页面中找到:
该函数中有metric_id这个变量,这是图表的id值,可以在控制台的图表页面中找到:

如果该函数能正常运行,那么会返还以下内容:
{
'data': {
'created_at': '2018-06-25 22:14:00',
'metric_id': 1,
'id': 20475,
'counter': 1,
'value': 576.4,
'calculated_value': 576.4,
'updated_at': '2018-06-25 22:14:32'
}
}
0x04 收尾
完整的脚本可以在以下地址中找到:
将脚本放置到相应的路径后,再通过crond进行定时调用:
*/1 * * * * root /usr/bin/python3 /usr/local/services_data/shell/cachethq/main_temp.py
0x05 结语
经过将近一个月的测试与观察,一切运行正常。接下来计划增加各类模块,以便对接zabbix的监控,从而实现自动化调整各个服务的状态。











 – pachosting")







服务器散热风扇的转速")
 – KVM & OpenVZ LAX02数据中心")

