
0x01 前言
在4月10日这天,我的博客遭遇了建站以来首次攻击,包含DDOS与CC攻击。虽然在调整防御策的时候经历过几次的短暂服务中断,但是整体来看还是挺成功的。
在遭受攻击前的过去2周里,我将站点的架构做了大调整,已经将数据库、PHP后端与前端进行分离。前端的nginx仅仅起到一个反向代理器的作用。
不知道攻击者的目的是什么,我的服务器仅运行着一个小博客,今天我针对这次事件做个详细的记录。
0x02 第一波攻击
- 12:45:32 服务器监控告警,上行带宽超过限制:
Subject: PROBLEM: enginx1 upload speed severe overload Message: Trigger: enginx1 upload speed severe overload Trigger date: 2018.04.10 12:45:31 Trigger status: PROBLEM Trigger age: 0m Trigger severity: Disaster Trigger URL: Item values: Outgoing network traffic on eth0 (enginx1:net.if.out[eth0]): 21.78 Mbps Original event ID: 13754613
- 随即通过SSH登入服务器,发现大量处于TIME_WAIT状态的连接:
#当时没有保留截图,这里仅展示当时所用的命令 [root@web ~]# netstat -anp | grep TIME_WAIT | wc -l
- 通过iftop发现众多IP访问HTTP端口:
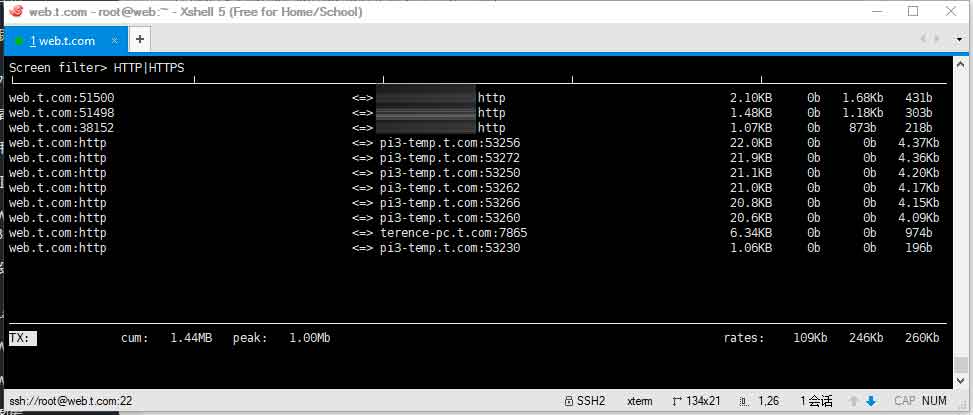
当时没有保留截图,这里仅展示当时所用的命令
- 确认问题后随即通过iptables封禁80端口传入的请求:
[root@web ~]# iptables -I INPUT -p tcp --dport 80 -j DROP
- 12:51:33 使用iptables封禁80端口后,流量随即下降,以下是告警消除通知:
Subject: OK: enginx1 upload speed severe overload Message: Trigger: enginx1 upload speed severe overload Trigger recovery date: 2018.04.10 12:51:31 Trigger status: OK Trigger age: 6m Trigger severity: Disaster Trigger URL: Item values: Outgoing network traffic on eth0 (enginx1:net.if.out[eth0]): 2.19 Mbps Original event ID: 13754613
- 上行带宽恢复的同时,我检查了用于日志分析的ELK集群,发现攻击开始于12:44:59,每秒并发在5k~8k之间,并且还在持续:
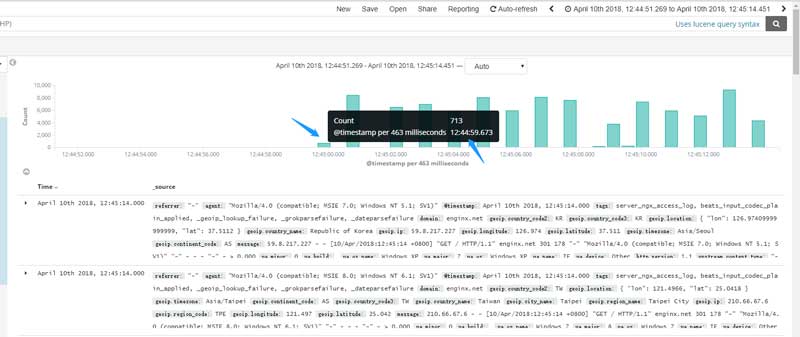
- 开始调整内核参数、启用防CC手段、调整fail2ban策略
- 13:15:00 首波攻击结束,越30分钟的时间内,nginx共计收到约3,030,617次请求,记录到来自世界各地的1600多个IP地址:
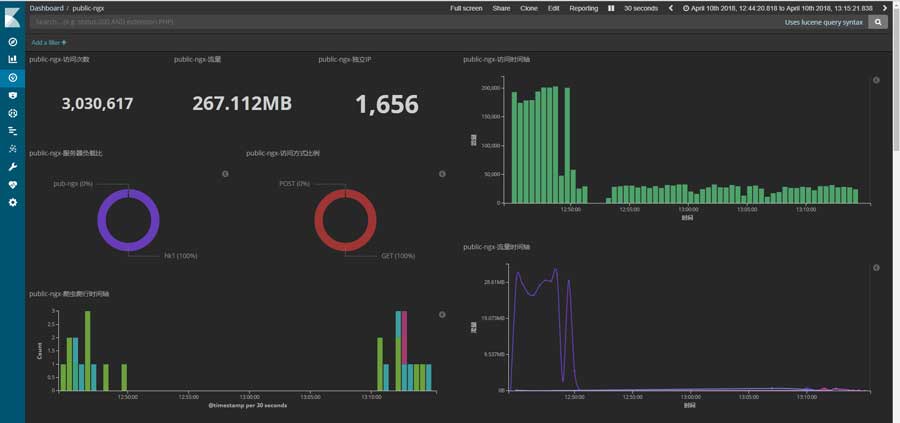
此次攻击所跑的流量并不大,nginx的日志如下:
222.235.176.229 - - [10/Apr/2018:12:45:30 +0800] "GET / HTTP/1.1" ngx.hk 301 178 "-" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; SV1)" "-" - - - "-" - > 0.000
可以看到,肉鸡通过HTTP协议访问我博客的域名,但我博客是强制使用HTTPS的,所以nginx返还了301给肉鸡。想不到肉鸡居然跟随了301进行跳转,生成了以下日志:
222.235.176.229 - - [10/Apr/2018:12:45:03 +0800] "\x00" - 400 166 "-" "-" "-" - - - "-" - > 0.000
所以每次攻击都会产生2次请求,这对我服务器的CPU与网络都造成极大的影响。
0x03 第二波攻击
我还以为攻击就这样结束了,然而并不是,在我正准备洗澡的时候,第二波攻击来了。
- 20:20:33 服务器监控告警,上行带宽超限:
Subject: PROBLEM: enginx1 upload speed severe overload Message: Trigger: enginx1 upload speed severe overload Trigger date: 2018.04.10 20:20:31 Trigger status: PROBLEM Trigger age: 0m Trigger severity: Disaster Trigger URL: Item values: Outgoing network traffic on eth0 (enginx1:net.if.out[eth0]): 39.52 Mbps Original event ID: 13766221
其实这一波攻击不应该成功的,因为我在回到家后多次对fail2ban的策略进行调整,导致上午ban掉的IP全被释放了,因此第二波攻击才有机可乘。
- 20:28:00 受限于fail2ban的性能,在经过8分钟后,已经快把所有的恶意IP都拉到黑名单了:
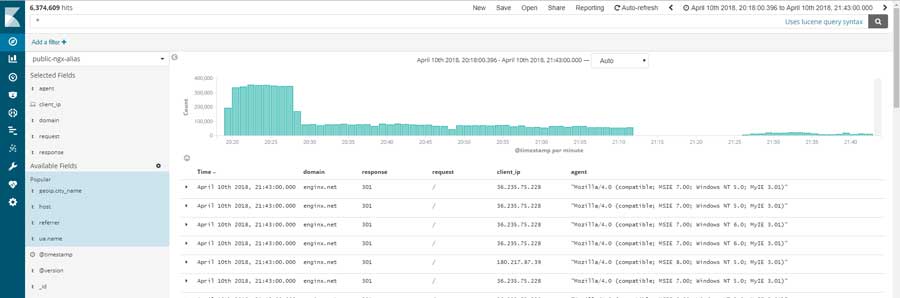
可能是因为攻击者的肉鸡都已经打完,连接数在缓慢地下降,而我的站点已知处于正常运行的状态。这一波的攻击从8点20分左右一直持续到11号的0点前后才结束。
0x04 防御
0x04.1 网站架构
我博客的架构在3月底至4月初已经完成改造,详细的描述我会在后期撰写文章说明,这里先描述下大体情况。
用户访问到的服务器仅用于前端,仅运行着nginx用于反向代理。我站点的mariadb、apache与PHP已经迁走,甚至zabbix proxy server也已经完成迁移。因此,用户访问到的页面都是缓存在本地的静态页面,只会对带宽造成压力,而后端依然坚挺。
我的后端运行着mariadb、Apache与PHP,且为双节点热备模式:一台运行在我家里的服务器中,另一台则运行在某云服务商的VPS中。
其中,运行在我家中的节点为主节点,在心跳包正常的情况下,所有需要后端请求的流量都会发送至这里。为了安全起见,一切需要登入后台的操作仅能在我家中操作,通过公网访问敏感目录一律返还403。
另外还解决了双节点的文件、session与数字证书同步等问题。
最后,所有静态文件都使用CDN进行分发,减轻前端服务器的压力。
这个架构较以前的一箩筐模式在抗攻击能力上有质的飞越:
- 当遭受攻击时,无需担心后端崩溃,可在后端建立WAF,对特定的客户IP进行拦截;
- 当遭受攻击时,通过前端服务器可以更便捷地拦截流量;
- 当遭受攻击时,可以随时调整DNS记录,通过分流肉鸡流量进行防御;
- 静态页面能有效提升防御能力
- … …
更多内容与实现方式计划在新文章中详细阐述。
0x04.2 HttpGuard
HttpGuard原本是一个开源项目,但是作者已经转为收费服务了。但是开源版本的源代码依旧可以在GitHub中下载并安装使用,简单的安装与配置可以参考以下文章:
原本我并没有启用HttpGuard,在遭受攻击后重新调整并启用防御功能。
首先启用被动防御,限制请求模块:
limitReqModules = { state = "On" , maxReqs = 100 , amongTime = 60, urlProtect = baseDir.."url-protect/limit.txt" },
每分钟请求超过100次的访客将会被要求输入验证码:
blockAction = "captcha",
因为我站点中的静态文件使用了CDN,所以在正常浏览情况下,同时打开多个页面也不会出发该规则。
因为肉鸡中的自动化程序不会输入验证码,在超过10次失败后将被拉黑24小时:
captchaToIptables = { state = "on", maxReqs = 10 , amongTime = 10},
blockTime = 86400,
whiteTime = 1800,
但是这个设定并不会调用iptables,而是返还HTTP响应码,默认情况下是返还444,但为了方便fail2ban统计,我将返还的响应码改为403:
#打开并修改以下文件中的第561行
vim guard.lua
#拒绝访问动作
function Guard:forbiddenAction()
ngx.header.content_type = "text/html"
ngx.exit(403)
但是我并未就此罢休,我还设置了自动启用的防御模块:
autoEnable = { state = "On", protectPort = "80", interval = 10, normalTimes = 3,exceedTimes = 2,maxConnection = 150, ssCommand = "/usr/sbin/ss" ,enableModule = "redirectModules"},
autoEnable = { state = "On", protectPort = "443", interval = 10, normalTimes = 3,exceedTimes = 2,maxConnection = 150, ssCommand = "/usr/sbin/ss" ,enableModule = "redirectModules"},
当在2次检查中,10秒内的连接数超过150,则启用重定向模块。一般情况下,CC攻击一般不会跟随跳转,所以这个重定向模块会有一定的用处,但对SEO则是一个灾难,所以该模块仅在必要时启用。
0x04.3 iptables & netstat & iftop
这三款软件在遭受攻击时非常有用,首先是iptables,在设置防御或者拦截规则时,首先采用丢包的模式而不是拒绝,因为丢包不需要给客户端返还内容,可以节省带宽,也可以起到一个迷惑攻击者的作用。
另外,在手动添加拦截规则时建议将规则插入到第一行,而不是最后一行,这样可以确保规则一定会生效。但是这种临时的规则并不需要保存,所以需要删除规则时,仅需要reload即可:
iptables -I INPUT -p tcp --dport 80 -j DROP
- -I:将规则插入到INPUT链的首行
- -p:匹配TCP协议
- –dport:首访端口为HTTP的80端口
- -j:将数据包丢弃
而netstat则可以检查当前的网络连接情况,例如:
[root@web ~]# netstat -anp | grep nginx tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 1644/nginx: master tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN 1644/nginx: master tcp 0 0 10.1.1.14:80 10.1.2.73:12135 ESTABLISHED 1645/nginx: worker tcp 0 0 10.1.1.14:80 10.1.1.22:53422 ESTABLISHED 1645/nginx: worker tcp 0 0 10.1.1.14:80 10.1.2.73:10819 ESTABLISHED 1646/nginx: worker tcp 0 0 10.1.1.14:80 10.1.2.73:13655 ESTABLISHED 1645/nginx: worker tcp 0 0 10.1.1.14:80 10.1.1.22:53430 ESTABLISHED 1645/nginx: worker tcp 0 0 10.1.1.14:80 10.1.2.73:11905 ESTABLISHED 1646/nginx: worker tcp 0 0 10.1.1.14:80 10.1.1.22:53428 ESTABLISHED 1645/nginx: worker tcp 0 0 10.1.1.14:80 10.1.2.73:14674 ESTABLISHED 1646/nginx: worker tcp 0 0 10.1.1.14:80 10.1.1.22:53438 ESTABLISHED 1645/nginx: worker tcp 0 0 10.1.1.14:80 10.1.2.73:12352 ESTABLISHED 1646/nginx: worker tcp 0 0 10.1.1.14:80 10.1.1.22:53352 ESTABLISHED 1646/nginx: worker tcp 0 0 10.1.1.14:80 10.1.1.22:53418 ESTABLISHED 1646/nginx: worker tcp 0 0 10.1.1.14:80 10.1.1.22:53420 ESTABLISHED 1646/nginx: worker
当需要统计某个状态的连接数时,可以使用以下命令:
[root@web ~]# netstat -anp | grep nginx | grep ESTABLISHED | wc -l 13
在遭受攻击时,服务器可能变得非常缓慢,所以命令越简单越好。
最后是iftop,一款实时展示网络连接情况的软件,使用iftop命令打开展示界面后,分别按下以下按键:
- t:在同一行内展示上下行情况,节省空间
- T:展示总流量
- p:展示端口
最后的界面应该类似这样的:
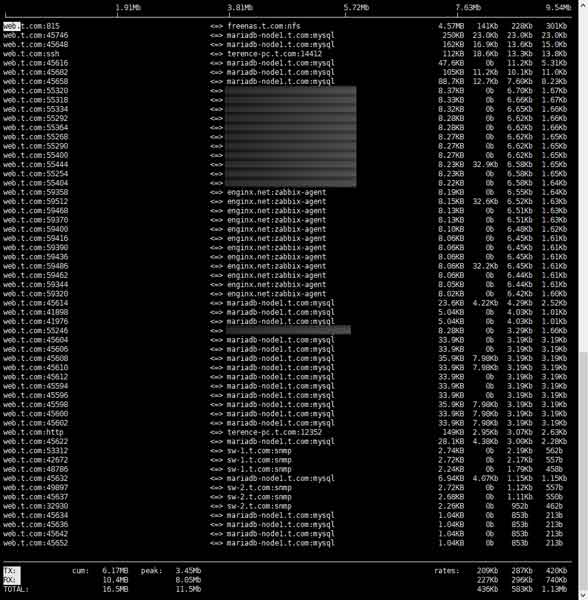
但是这里面的端口太混乱了,我只需要HTTP与HTTPS的访问情况,这时候按下小写字母“L”,输入:
HTTP|HTTPS
后回车即可查看HTTP与HTTPS协议的连接情况。
先使用软件分析实际情况,然后进行分析,最后进行策略调整。
0x04.4 fail2ban
fail2ban的基本安装配置可以参考以下文章:
在第一波攻击的时候我就调整了策略,收紧对nginx日志中响应码为403的访客的控制,一旦超过限值则调用iptables将其请求丢弃:
[ngx-log-40x]
enabled = true
port = http,https
filter = ngx-40x
logpath = /var/log/nginx/access.log
action = %(banaction)s[name=%(__name__)s-tcp, port="%(port)s", protocol="tcp", chain="%(chain)s", actname=%(banaction)s-tcp]
%(mta)s-whois[name=%(__name__)s, dest="%(destemail)s"]
maxretry = 10
findtime = 1800
bantime = 86400
ignoreip = 127.0.0.1
一般情况下不会触发403响应码,如果客户在30分钟以内触发超过10次403状态码,则拉黑24小时。
但通过检查ELK中的分析发现,肉鸡触发最多的并不是403,而是301与200。为此,针对我的实际情况,制定了以下规则
[ngx-log-30x]
enabled = true
port = http,https
filter = ngx-30x
logpath = /var/log/nginx/access.log
action = %(banaction)s[name=%(__name__)s-tcp, port="%(port)s", protocol="tcp", chain="%(chain)s", actname=%(banaction)s-tcp]
%(mta)s-whois[name=%(__name__)s, dest="%(destemail)s"]
maxretry = 50
findtime = 1800
bantime = 86400
ignoreip = 127.0.0.1
[ngx-log-20x]
enabled = true
port = http,https
filter = ngx-20x
logpath = /var/log/nginx/access.log
action = %(banaction)s[name=%(__name__)s-tcp, port="%(port)s", protocol="tcp", chain="%(chain)s", actname=%(banaction)s-tcp]
%(mta)s-whois[name=%(__name__)s, dest="%(destemail)s"]
maxretry = 200
findtime = 1800
bantime = 86400
ignoreip = 127.0.0.1
0x04.5 nginx
但是在第二波攻击时我又发现访问次数上限太高,fail2ban的压力太大。因此,我利用nginx自带的limit_req模块进行限流:
#定义zone limit_req_zone $binary_remote_addr zone=main:50m rate=140r/s; #调用zone并定义令牌桶 limit_req zone=main burst=150 nodelay; #超限将返还403 limit_req_status 403;
配置完nignx后可以发现可疑的IP确实被fail2ban中检测403的jail规则拦截了。
但我并没有删除fail2ban中检测301与200的规则,这部分还需要进一步测试,以便分析性能与可靠性。
0x04.6 内核
针对TIME_WAIT的问题,我选择通过调整内核的方式进行优化:
#修改超时时间为30秒,某些情况可以进一步降低该值 net.ipv4.tcp_fin_timeout = 30 #将keepalive的发送频率降低为20分钟一次 net.ipv4.tcp_keepalive_time = 1200 #开启SYN Cookies,当SYN队列溢出时启用Cookies net.ipv4.tcp_syncookies = 1 #开启TIME-WAIT sockets重用功能 net.ipv4.tcp_tw_reuse = 1 #开启TIME-WAIT sockets快速回收功能 net.ipv4.tcp_tw_recycle = 1 #加大SYN队列 net.ipv4.tcp_max_syn_backlog = 8192 #最大TIME_WAIT保持数,超过将全部清除 net.ipv4.tcp_max_tw_buckets = 5000
调整后发现异常的连接数大幅度减少。
0x05 数据
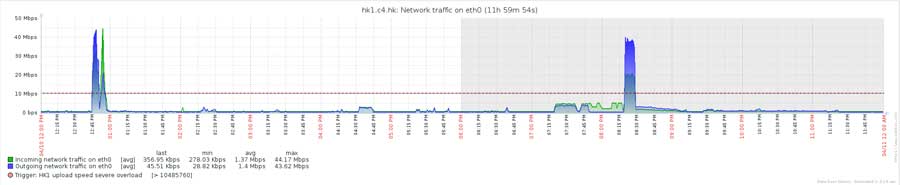
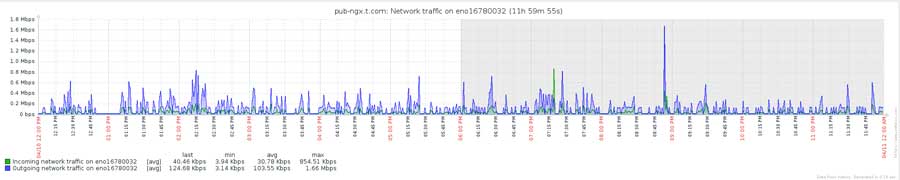
上下行峰值为44Mbps左右:
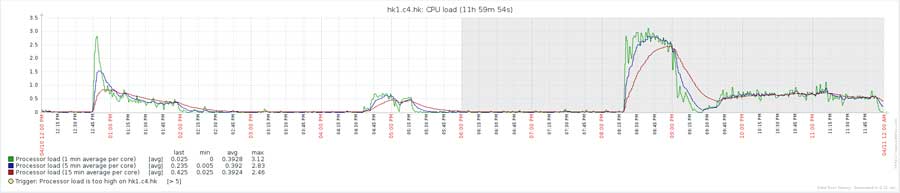
CPU负载情况如下图:
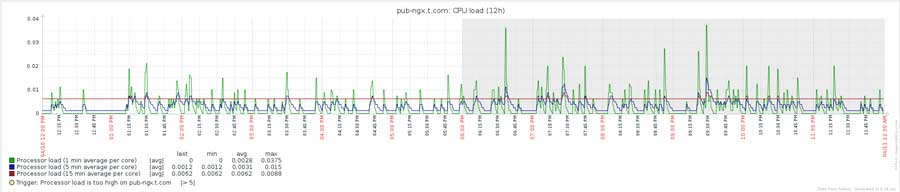
因为前端服务器有缓存与防护,所以后端服务器一切正常:
流量也正常:
数据库也未见异常:

从中午12点至第二天的0点这中间的12小时里,共计接受了10,178,740次访问、流量为1.058GB,共记录到3,004个IP地址:
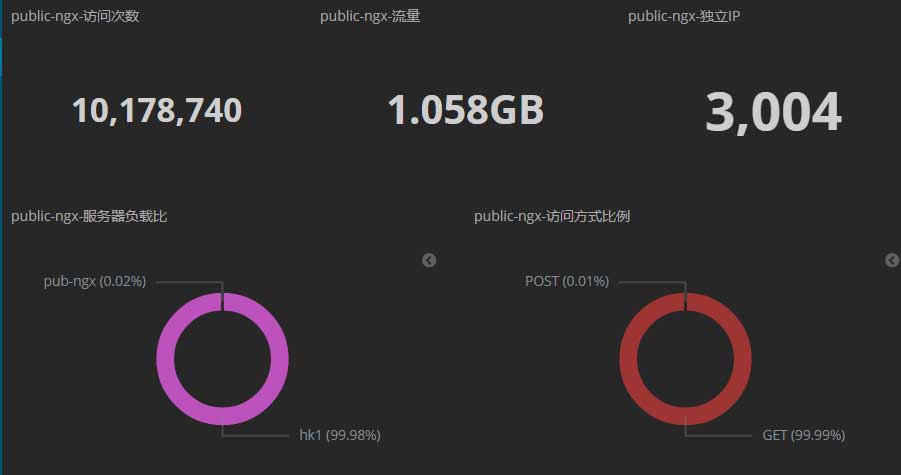
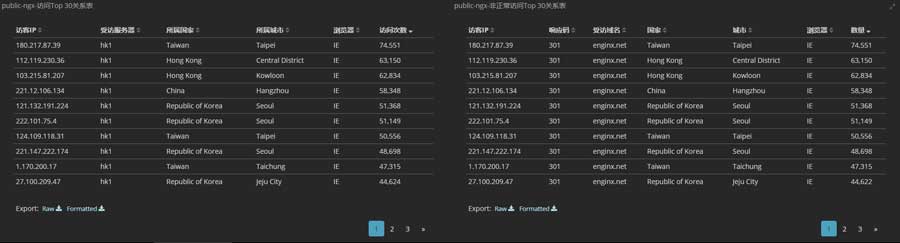
流量与请求分布情况如下图:

肉鸡主要来自亚洲,大部分来自我国:
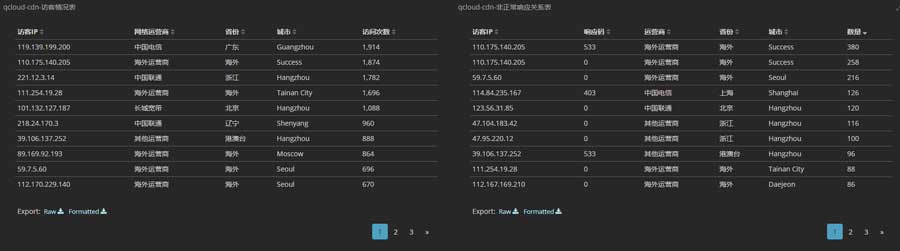
CDN也受到波及,跑了一波流量,但随后触发了抗CC规则,IP被拉黑了:
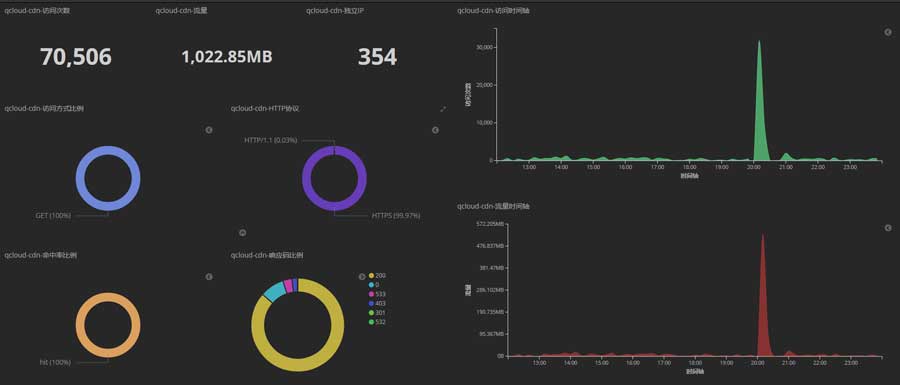
攻击CDN的肉鸡大多来自亚洲,以我国的IP为主:
0x06 结语
我博客的架构与防护软件的功劳不可小觑,另一部分因素是攻击者的肉鸡不够了,不过从大体看来,这次攻击的肉鸡质量不错。
我比对了两波攻击的IP,发现大部分都是一样的。肉鸡居然可以用那么久,由此可见,此次肉鸡的质量非常好。
只是不明白为什么要选择我这个小博客作为目标 🙁












 – 日本GMO")








