
0x01 前言
晚上心血来潮向更新首页,发现本站所用的wordpress模板的demo有个样式非常合适,在进行测试的时候无意间导入大量文章,于此同时对通过邮件订阅我博客的朋友发送大量通知邮件,造成极其严重的影响。
经过一番折腾,我发现模板厂商自开发的编辑器存在问题,在编辑的时候会出现大量js错误,导致一些功能无法正常使用,使得我的页面破破烂烂。正想放弃的时候发现原来的首页数据已经丢失,而且媒体库和文章库等被导入大量demo数据,同时数据库也遭受“污染”,已经无法通过常规方法还原。
所以,这次事故被定性为生产事故,需要紧急进行灾难恢复。因为我的博客数据每天备份,所以只需要还原到前一天的数据即可。
0x02 web服务器
我是用netbackup(下称NBU)对虚拟机进行备份,通过NBU对接vCenter,从而调用vCenter的API进行虚拟机的快照工作,最终将快照数据存放到NBU的数据存储中。
因为我服务器的磁盘空间较为庞大,所以web服务器备份我都以全量备份进行。对于web服务器,而且其没用任何依赖关系,web服务器中运行着lsync会将另一个web服务器中的脏数据同步删除,所以直接还原即可。首先找到相关备份文件:

而后选中镜像并单击恢复按钮,在弹出的对话框中确认还原到原始路径:
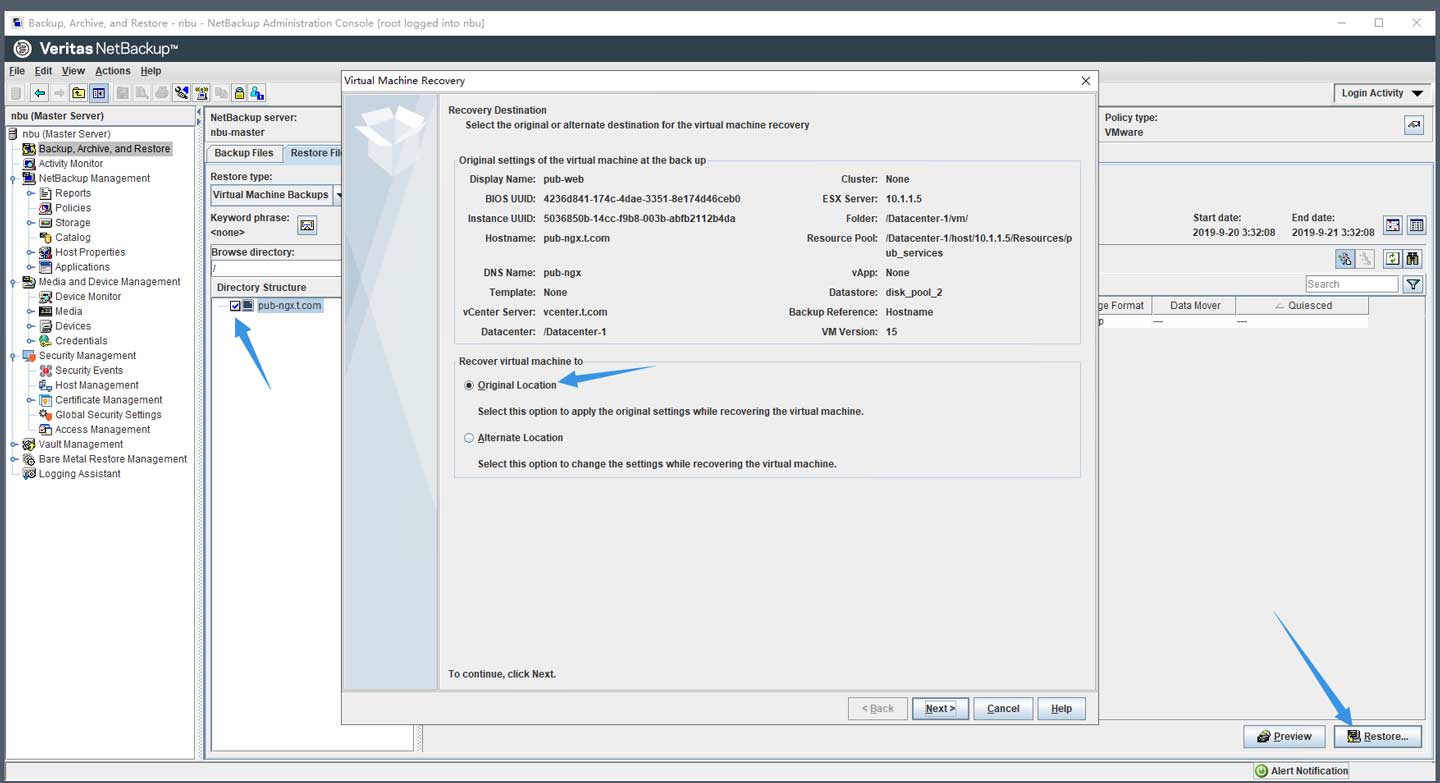
确认数据的传输途径,具体请参考软件文档,如果不确认,可以全选,但在某些情况可能不是最优选择或者出现一些奇怪的问题:
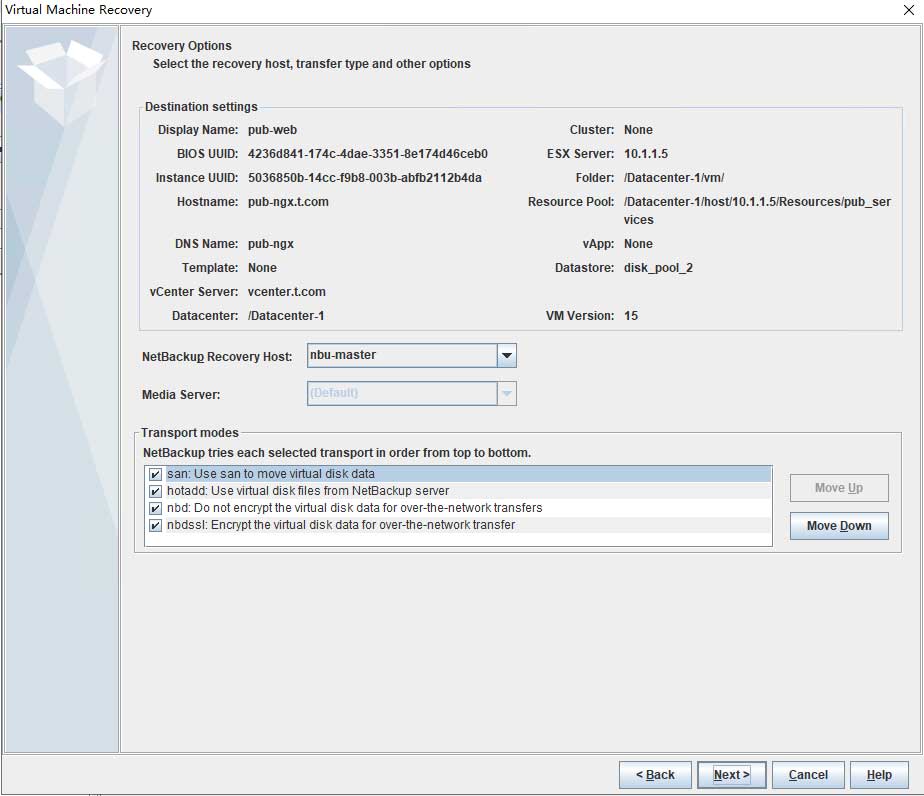
紧接着勾选还原虚拟机BIOS UUID和实例UUID,覆盖到当前的虚拟机位置,移除光盘驱动器、串口等信息,建议选择精简置备的磁盘模式,可极大程度提高磁盘使用率,但对IO密集型的虚拟机会带来IO性能稍微下降的问题:
 在实施还原前需要进行检查,通过后即可开始:
在实施还原前需要进行检查,通过后即可开始:
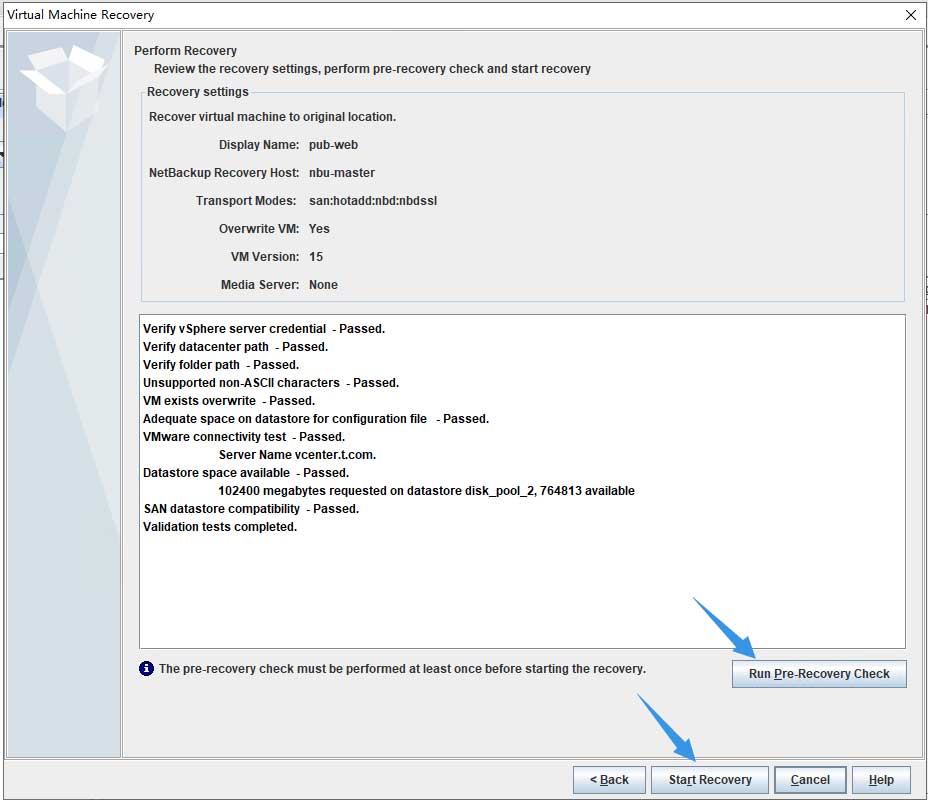
接下来可以切换到任务进程视图,检查任务执行情况:

还原流程结束后再回到vCenter启动虚拟机即可。因为是全量备份和全量还原,同时该虚拟机中运行的服务没用任何依赖性且没用部署集群等,所以还原过程较为简单粗暴。
0x03 数据库
数据库有那么一点点复杂,因为数据库是以MariaDB Galera集群实现的多master同步需求,我的集群共有3个节点,均为master。
因为数据已经被污染,也就是说数据已经同步到各个节点。如果直接还原我家中的节点,因为备份时间为前一天,最终在数据库启动的时候会拉取其他节点包含脏数据的版本到本地,无法实现数据库还原的目的。
所以解决问题的流程是:
- 保留现有数据库集群节点
- 将前一天的备份还原至其他地方并重命名
- 从还原的数据库中dump数据库数据
- 删除现有节点中的数据
- 导入前一天的数据
- 等待同步,完成
NBU还原历史备份的流程与web服务器类似,但在开始时需选择备用路径:
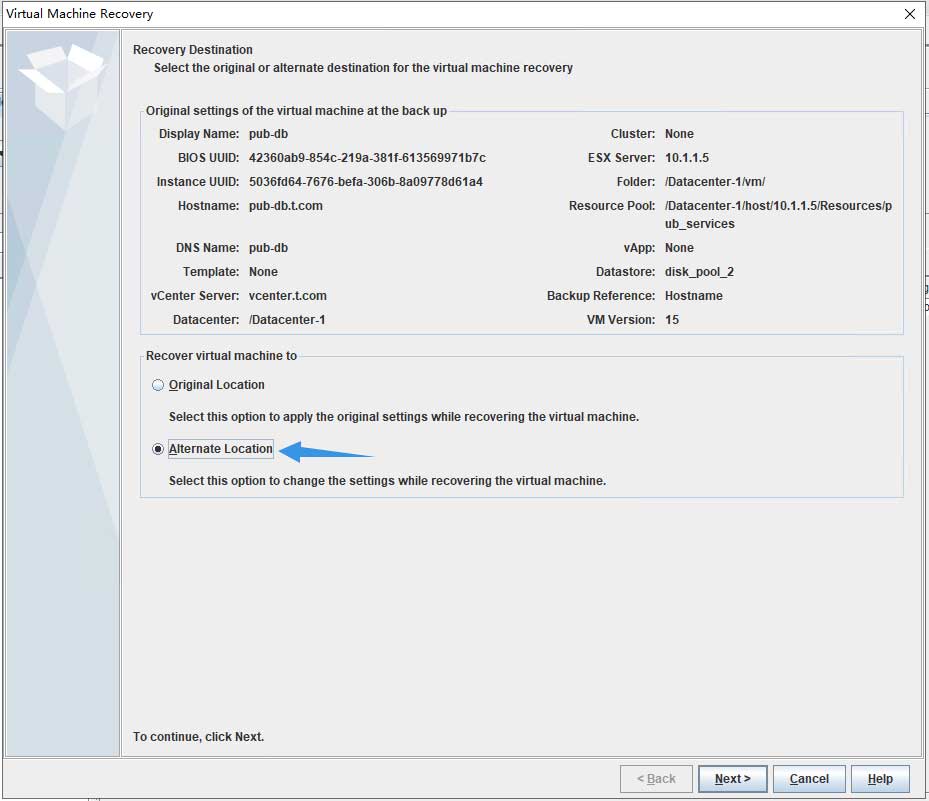 在传输方式界面还需要选择存放位置的信息,并且建议更改虚拟机名称:
在传输方式界面还需要选择存放位置的信息,并且建议更改虚拟机名称:
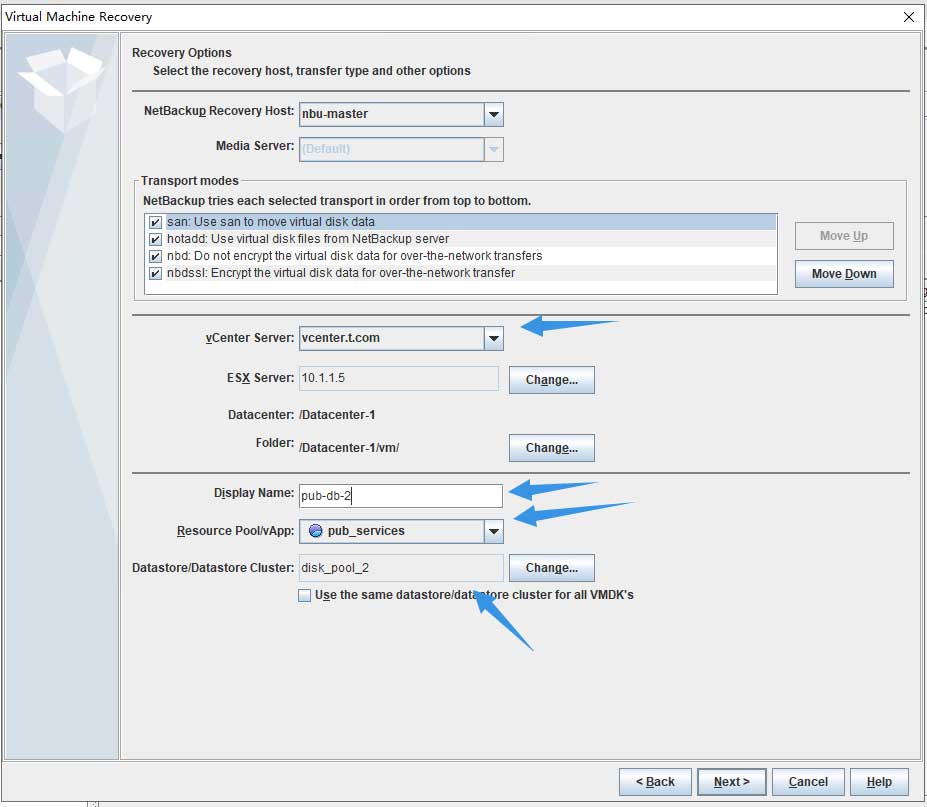
后面会检查数据存储:
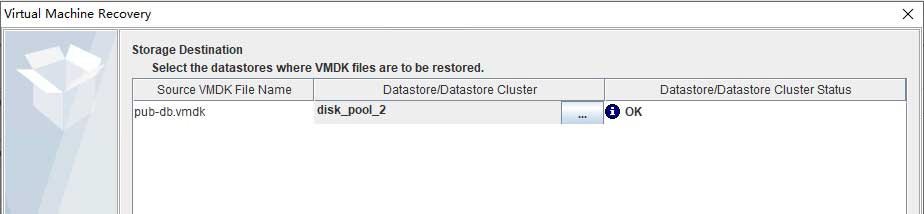
要求选择合适的端口组:
最后是测试:
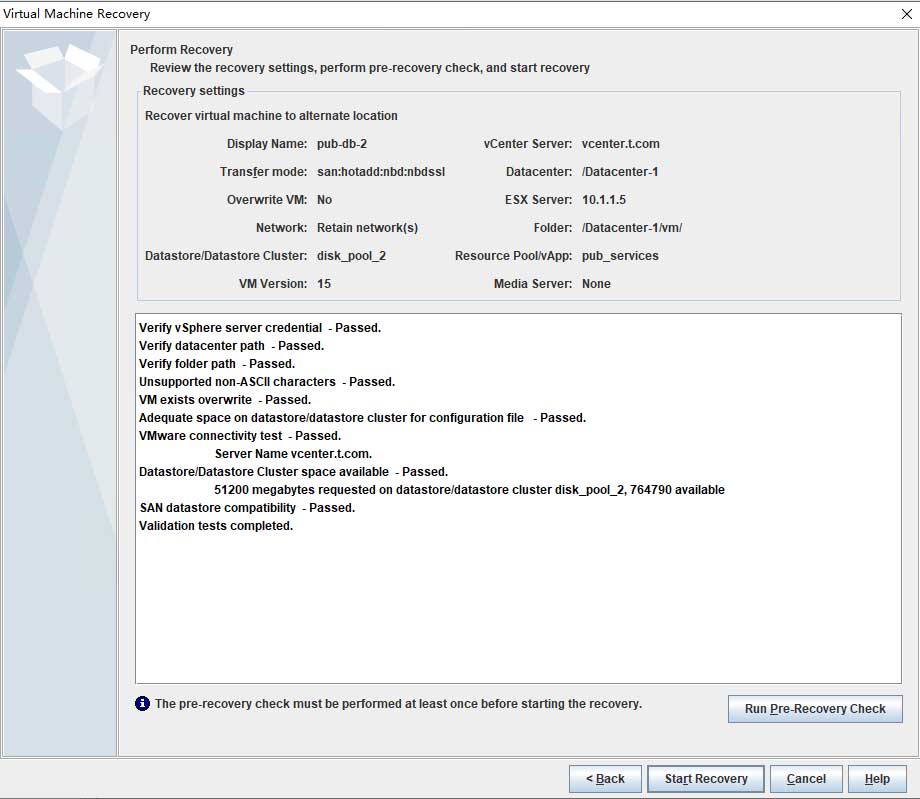
完成还原工作后,在启动虚拟机前需要删除虚拟机的网卡,因为我的数据库是设为系统启动后自行启动的,而后会自动加入数据库集群;另外,网卡是手动模式,需要将其修改为DHCP模式,以避免IP冲突的问题:
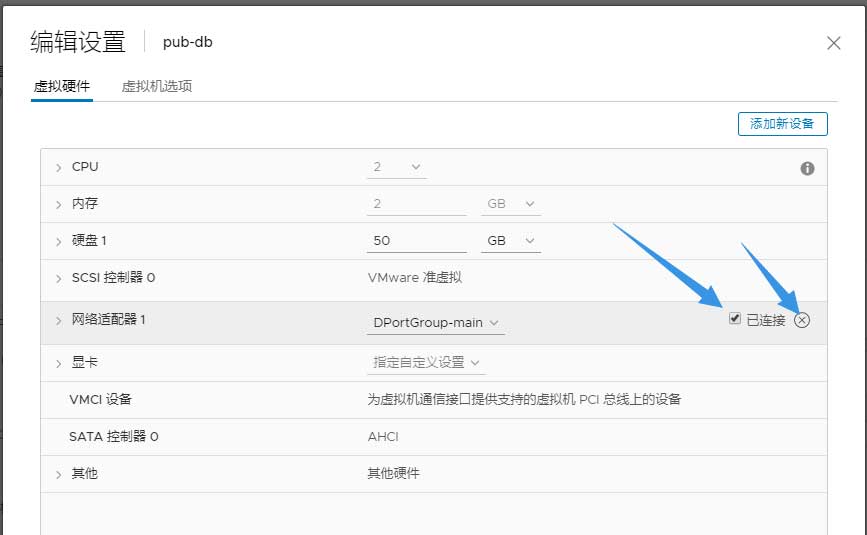
建议删除还原的网卡并重新添加,避免MAC地址重复。网卡使用nmtui配置:
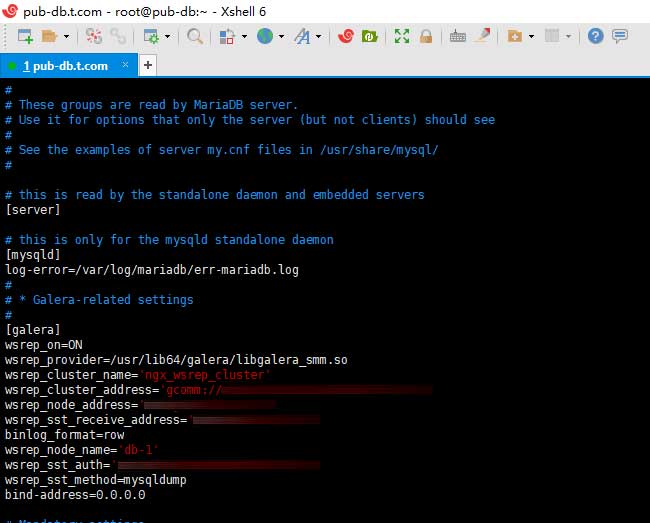
最后删除MariaDB配置文件中galera集群的配置信息:
完成后重启虚拟机,确认MariaDB启动后即可使用mysqldump命令导出数据并通过sftp等方式传输到生产环境集群中的某一节点里。
在生产环境的节点中删除相应数据库的所有表,最后导入即可,数据会自动在各个节点中同步。
0x04 结语
受限于机械磁盘IO的问题,数据还原用了20多分钟。最终,经过半小时的紧张折腾,我的博客恢复了。
在此向遭受邮件骚扰的订阅者们道歉,下次类似的测试会在隔离的测试环境中进行。





















