
0x01 前言
elastic stack在4月11日发布了7.0正式版,而我也在第一时间完成家里测试环境的升级工作。因为我是从6.7.0升级到7.0的,同时经过x-pack升级助手的检查,升级前后均没问题。
但在升级filebeat之后却出现大量错误日志,而在此之前,我QQ群内一位朋友也发现类似的问题,而他找出了报错的原因。
0x02 BUG
首先是日志,为了方便查看,我对日志格式做了些调整:
[2019-04-14T23:17:43,051][WARN ][logstash.outputs.elasticsearch]
Could not index event to Elasticsearch. {:status=>400, :action=>["index",
{:_id=>nil, :_index=>"public-nginx-alias", :_type=>"_doc", :routing=>nil},
#<LogStash::Event:0x2efc3092>],
:response=>{
"index"=>{
"_index"=>"public-nginx-index-v1",
"_type"=>"_doc",
"_id"=>"7NZsHGoB4Cf78Hum8oUF",
"status"=>400,
"error"=>{
"type"=>"mapper_parsing_exception",
"reason"=>"failed to parse field [agent] of type [text] in document with id '7NZsHGoB4Cf78Hum8oUF'",
"caused_by"=>{
"type"=>"illegal_state_exception",
"reason"=>"Can't get text on a START_OBJECT at 1:206"}
}
}
}
}
以上是logstash7.0的日志,而且这些日志只出现在使用7.0版本的filebeat服务器中。由以上日志信息可以发现处理名为agent的字段失败,而出现illegal_state_exception的原因一般是字段异常。
经过群友的耐心debug发现这个问题是因为我以前文章中logstash过滤器的grok规则导致的。
如果大家有关注我的博客,可以在以下文章中找到相关的nginx日志的grok规则:
以上文章中均包含以下字段:
# 分词规则
%{QS:agent}
# useragent分析规则
useragent {
source => "agent"
target => "ua"
}
它匹配的是日志中的useragent,如下所示:
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36"
上述的分词规则会匹配被双引号包裹的相关字符,并赋值给名为agent的字段,最终导入到elasticsearch,结果如下:

而useragent分析规则则是从agent字段中取值并调用useragent 插件处理,处理完的结果赋值给名为ua的字段,结果如下:
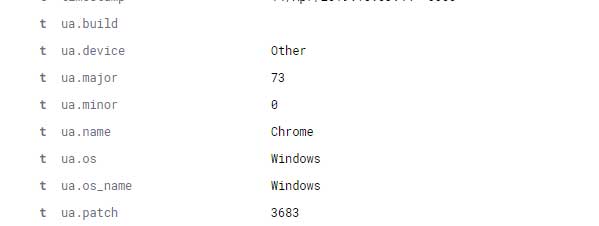
"ua": {
"os_name": "Windows",
"minor": "0",
"build": "",
"name": "Chrome",
"os": "Windows",
"device": "Other",
"patch": "3683",
"major": "73"
},
这个日志分词和useragent分析功能在7.0之前是正常的;但从7.0开始,agent字段属于内置的保留字段,主要记录着该beat所在的主机的一些信息:
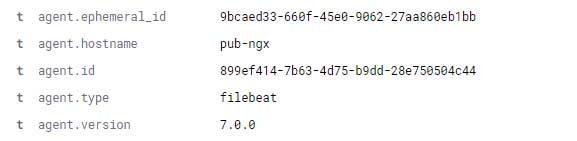
"agent": {
"id": "899ef414-7b63-4d75-b9dd-28e750504c44",
"type": "filebeat",
"hostname": "pub-ngx",
"version": "7.0.0",
"ephemeral_id": "9bcaed33-660f-45e0-9062-27aa860eb1bb"
},
所以问题很简单,就是新旧版本的字段冲突了。
0x03 DEBUG
既然字段名冲突,那只需要修改字段名即可,但实际上没那么简单。
因为数据是不断传入logstash进行处理的,所以logstash和elasticsearch的服务不能长时间中断;其次是历史数据不能丢失。
因为我只有一个logstash节点,所以修改过滤器规则后重启logstash会导致一小段时间的服务中断,而且服务中断期间的日志会丢失。但对于我的环境来说,这一部分日志的丢失是可以接受的;如果需要高可用,则建议部署多个logstash节点后再进行调整。
首先修改过滤器规则:
[root@logstash6-node1 ~]# cat /etc/logstash/conf.d/10-nginx-fliter.conf
filter {
if "server_ngx_access_log" in [tags] {
grok {
match => { "message" => "%{IPORHOST:client_ip} - (%{GREEDYDATA:auth}|-) \[%{HTTPDATE:timestamp}\] \"(%{WORD:verb} %{GREEDYDATA:request} HTTP/%{NUMBER:http_version}|%{GREEDYDATA:request})\" (%{IPORHOST:domain}|%{URIHOST:domain}|-) %{NUMBER:response} %{NUMBER:bytes} %{QS:referrer} %{QS:ngx_ua} \"(%{IPORHOST:x_forword_ip}, .*|%{IPORHOST:x_forword_ip}|unknown|-)\" (%{IPORHOST:upstream_host}|-)(\:%{NUMBER:upstream_port}|) (%{NUMBER:upstream_response}|-) (%{WORD:upstream_cache_status}|-) \"%{NOTSPACE:upstream_content_type}(; charset\=%{NOTSPACE:upstream_content_charset}|)\" (%{NUMBER:upstream_response_time}|-) > %{NUMBER:request_time}" }
}
geoip {
source => "client_ip"
}
geoip {
source => "x_forword_ip"
target => "x_forword_geo"
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
useragent {
source => "ngx_ua"
target => "ua"
}
mutate {
split => { "x_forword" => ", " }
}
}
}
我修改了grok规则中与useragent插件中的字段名称为ngx_ua,修改完成后即可重启logstash。
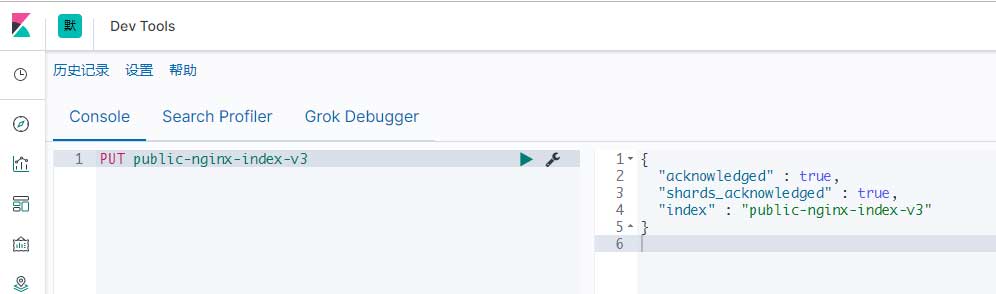
然后需要使用kibana中的Dev Tools调用elasticsearch API。首先建立一个新的索引:
PUT public-nginx-index-v3
然后修改别名的指向,在此之前先获取目前的别名指向情况:
GET _cat/aliases

接下来即可进行修改:
POST /_aliases
{
"actions": [
{
"remove": {
"index": "public-nginx-index-v2",
"alias": "public-nginx-alias"
}
},
{
"add": {
"index": "public-nginx-index-v3",
"alias": "public-nginx-alias"
}
}
]
}
成功执行该API后,所有数据都会写入到public-nginx-index-v3索引中。
完成上述步骤后才可以进行历史数据字段名称的修改,要不然有可能会使历史数据受损或遭到污染。
对于历史数据,我才用较为简单的手段处理:将历史数据中的agent字段的数据传递给新字段ngx_ua,而后删除旧字段,最终将数据写入新索引。
这一系列步骤我通过reindex API完成:
POST _reindex
{
"source": {
"index": "public-nginx-index-v2",
},
"dest": {
"index": "public-nginx-index-v3"
},
"script": {
"inline": "ctx._source.ngx_ua = ctx._source.remove(\"agent\"); "
}
}
上面命令的意思是将v2索引中的数据迁移至v3中,在这过程中将旧索引的agent字段赋值给新索引的ngx_ua字段后删除自身。
根据数据量的不同,reindex所需要的时间也各有长短,完成后即可删除该索引以减少空间消耗:
DELETE public-nginx-index-v2
0x04 结语
为了减少不必要的操作,确保数据安全与洁净,建议对历史数据操作前先通过快照API对数据做快照;另外,在进行实操前需进行全盘规划。
整个过程会对IO造成极大压力,请适当调整elasticsearch节点数以均衡负载,减少对线上业务的影响。






















