
0x01 前言
最近在审查网站日志,发现最勤奋的爬虫是Google,然后是bing、baidu和俄罗斯的yandex,访问我网站的访客最喜欢用chrome和Firefox。
但仔细检查发现有些爬虫的流量非常大,爬行次数甚至超过Google,还有一些很明显是一些脚本、渗透软件或非正常用户的UA。这些都是我屏蔽的对象。
0x02 准备
首先要准备naxsi,通过以下链接,你可以找到配置的方法:
然后还需要准备好需要屏蔽的UA,以下是我屏蔽的部分UA名称:
Go-http-client Java curl ApacheBench wget CRAZYWEBCRAWLER MJ12bot
0x03 配置
默认情况下,naxsi并没有添加UA相关的规则,所以我们需要手动编写规则。以下是相关规则:
MainRule "rx:Go\-http\-client|Java|curl|ApacheBench|wget|CRAZYWEBCRAWLER|MJ12bot" "msg:block User Agent" "mz:$HEADERS_VAR:User-Agent" "s:$UWA:8" id:10001;
我们将上面的规则拆开来看看:
- MainRule:表示这是一条匹配规则
- rx:这条规则采用正则进行匹配
- msg:这条规则的注释,并不会对匹配规则产生影响
- mz:匹配区域Match Zones,这里定义为匹配HTTP Headers里的User-Agent字段
- s:评分Score,如果访客UA匹配到这条规则,将为该请求在UWA这个计数器中加8分
- UWA:计数器,可以自定义
- id:这条规则的ID,建议将自定义规则的ID采用10000以后的数字
我的配置文件位于以下路径,请根据你的实际情况进行修改。将以下内容填入nasxi的规则文件中:
#打开文件 [root@web-t1 ~]# vim /usr/local/nginx/naxsi_core.rules #在文件底部填入以下内容 ############################# ## User Agent: 10000-11000 ## ############################# MainRule "rx:Go\-http\-client|Java|curl|ApacheBench|wget|CRAZYWEBCRAWLER|MJ12bot" "msg:block User Agent" "mz:$HEADERS_VAR:User-Agent" "s:$UWA:8" id:10001;
然后还需要修改虚拟空间的配置文件,在每个location字段中添加第16行中的CheckRule:
location ~ .*\.(js|css|jpg|jpeg|gif|png|woff|webp)$ {
proxy_pass http://10.1.1.2:8080;
expires max;
etag on;
SecRulesEnabled;
#LearningMode;
DeniedUrl "/RequestDenied";
CheckRule "$SQL >= 8" BLOCK;
CheckRule "$RFI >= 8" BLOCK;
CheckRule "$TRAVERSAL >= 4" BLOCK;
CheckRule "$EVADE >= 4" BLOCK;
CheckRule "$XSS >= 8" BLOCK;
CheckRule "$UWA >= 8" BLOCK;
}
CheckRule的作用是检查计数器的数值是否与设定的规则相匹配,如果匹配则进行相应的操作。
上面代码第16行的意思为:访客访问到这个location中的文件时,检查UWA这个计数器,如果计数器的数值大于或等于8,则进行BLOCK操作,否则放行。
然后使用一下命令重新加载nginx:
[root@web-t1 ~]# nginx -s reload
0x04 测试
上面的规则屏蔽了curl,那么下面使用curl进行测试:
MacBook-Air-Lan:~ terence$ curl https://ngx.hk <html> <head><title>403 Forbidden</title></head> <body bgcolor="white"> <center><h1>403 Forbidden</h1></center> <hr><center>nginx</center> </body> </html>
服务器直接返还了403,然后检查nginx日志:
[root@web-t1 ~]# tail -n 1 /var/log/nginx/error.log 2017/03/29 00:31:54 [error] 10533#0: *2418312 NAXSI_FMT: ip=119.139.57.82&server=ngx.hk&uri=/&learning=0&vers=0.55&total_processed=1713&total_blocked=73&block=1&cscore0=$UWA&score0=8&zone0=HEADERS&id0=10001&var_name0=user-agent, client: 119.139.57.82, server: ngx.hk, request: "GET / HTTP/1.1", host: "ngx.hk"
上面的日志中并没有指出访客使用的是什么UA而被屏蔽的,因为规则中使用了正则进行匹配,所以日志当作这是一个整体。如果需要知道用的是什么UA,则需要每个UA建立一条规则。
0x05 空UA
正常的访客肯定会带有UA字段的,所以我不希望空UA的访客访问我的网站。将下面内容添加到location块中即可:
if ($http_user_agent = "") {
return 403;
}
我还发现,空UA的访问绝大部分来自中国,而且数量还不少:
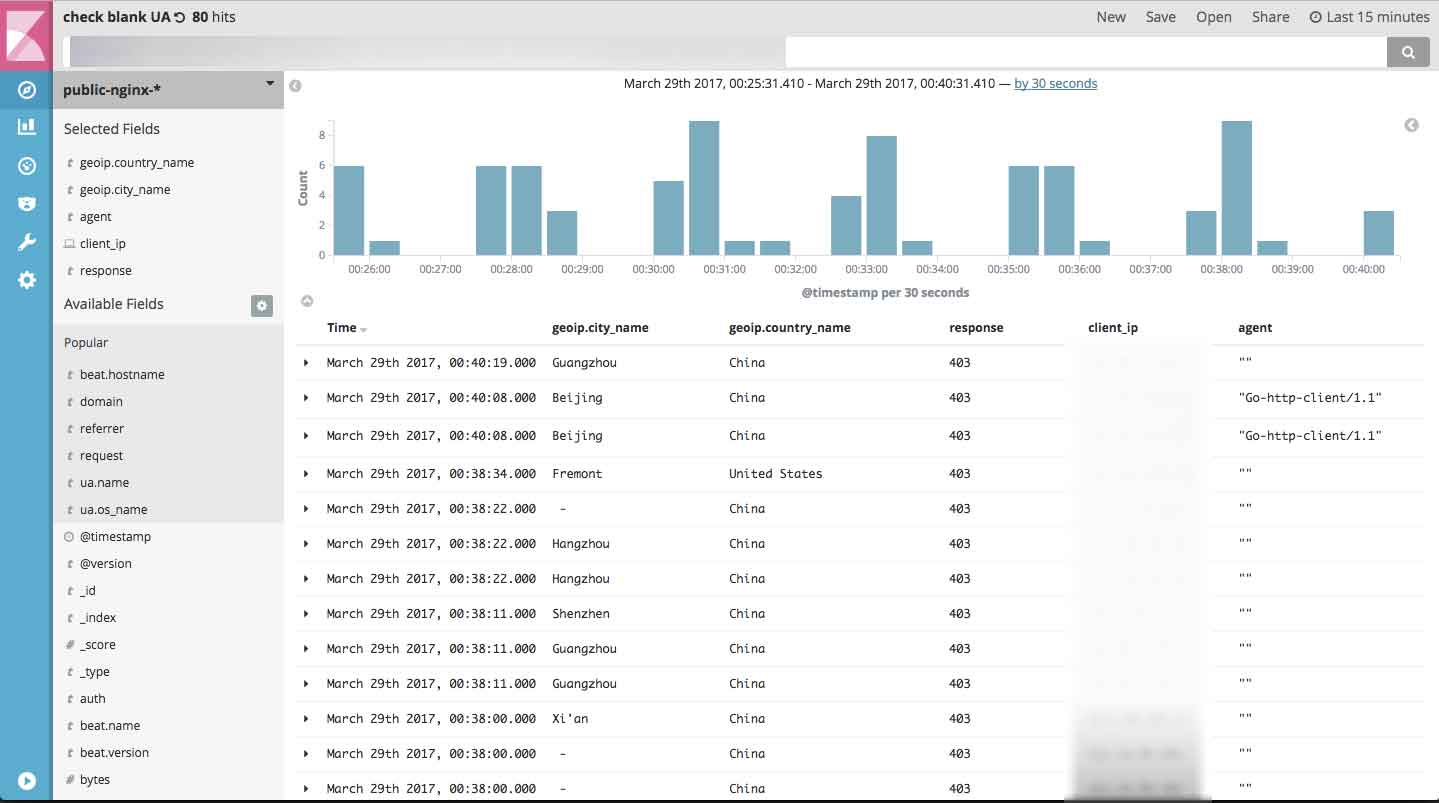
0x06 结语
对于一些另类的爬虫和商业爬虫,我都直接返还403。在了解爬虫的过程中我发现有一类是专门爬网站,然后将数据大包出售,或者吸引你购买他们的分析数据。这类爬虫对网站的压力非常大,其中有一个爬行的次数居然比Google还多,果断屏蔽。


















配置详解")



