
0x01 前言
在这个博客建立之初,我曾经为寻找一家可靠稳定的vps服务商而烦恼过一段时间,经过多番比较,最终选择Pachosting,这是当时写的一篇文章:
他是现在LayerStack的前身,经过多次升级换代,目前他们推出诸如LayerPanel v2.0等改进,为此,我也写过文章进行记录:
时至今日,我已经用他们的服务器将近4年。
0x02 LayerStack
针对他们的不足,我之前有写过文章:
相比较Pachosting的时代,LayerStack的CN2与国际线路的质量都出现下降,在带宽限制上不再宽松,当出现长时间占用带宽的情况时会被QOS,哪怕是在套餐内的带宽值。
在近几个月发现我所使用的套餐的带宽较之前减少了许多,被限制在10Mbps,这可能是突发带宽,因为套餐内保证的带宽值为4Mbpa。但对于CN2线路来说,这个限制是可以接受的,毕竟国内路由的CN2带宽比较贵。
另一个迫使我放弃LayerStack的因素是价格,在近期涌现出许多优质的使用CN2线路的服务商,价廉质优。在保证服务质量的同时提供更具有竞争力的价格,且能提供多语种工单服务、能提供多种不同类型的服务。
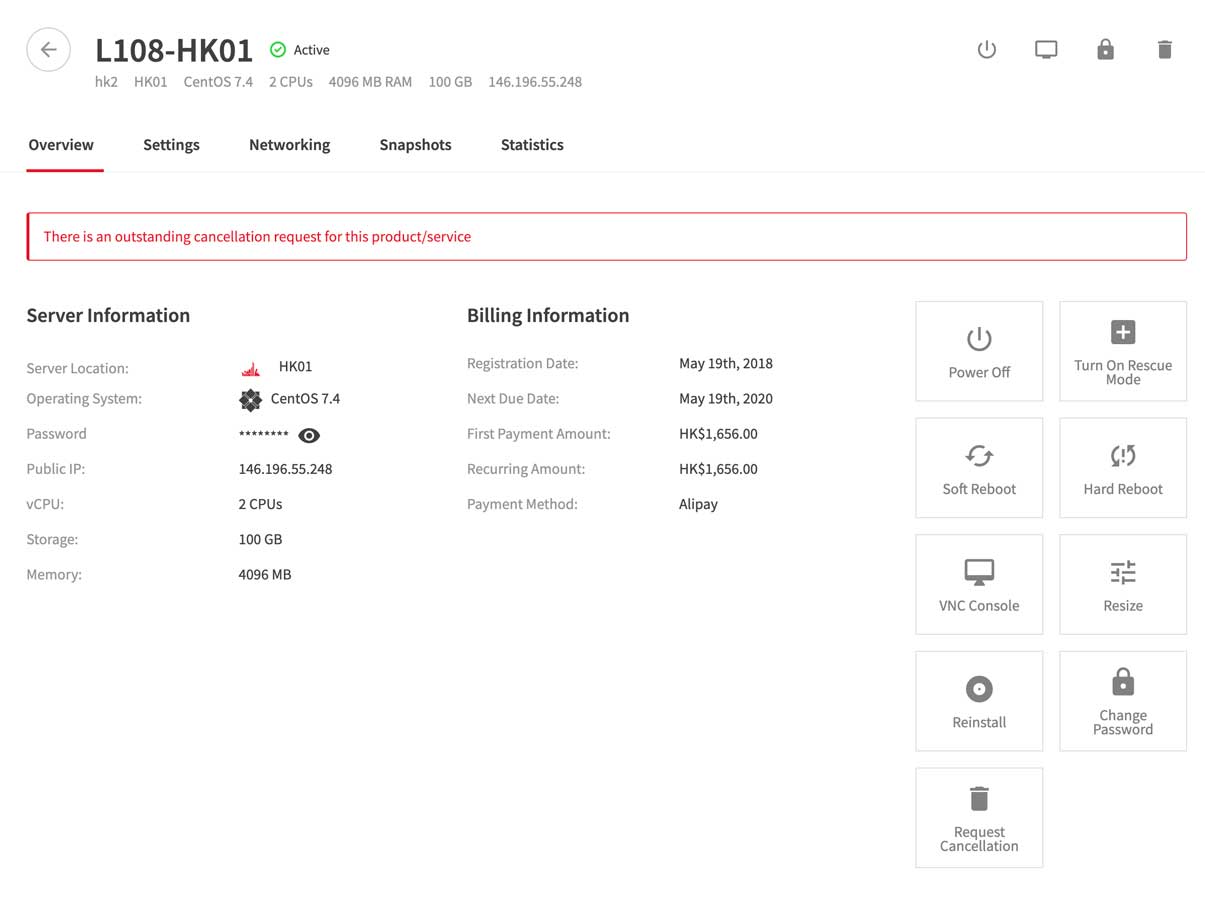
终于,我最后一台LayerStack服务器将在5月19日到期:
0x03 UOvZ
经过多番寻找与比较,我最终选择UOvZ作为LayerStack替代服务商。
首先UOvZ的价格更优,与此同时,CN2带宽比LayerStack要大,它还能提供独立服务器、NAT服务、大带宽服务器以及高防服务器等多种不同的服务,而我选择位于香港沙田机房的HK D1套餐:
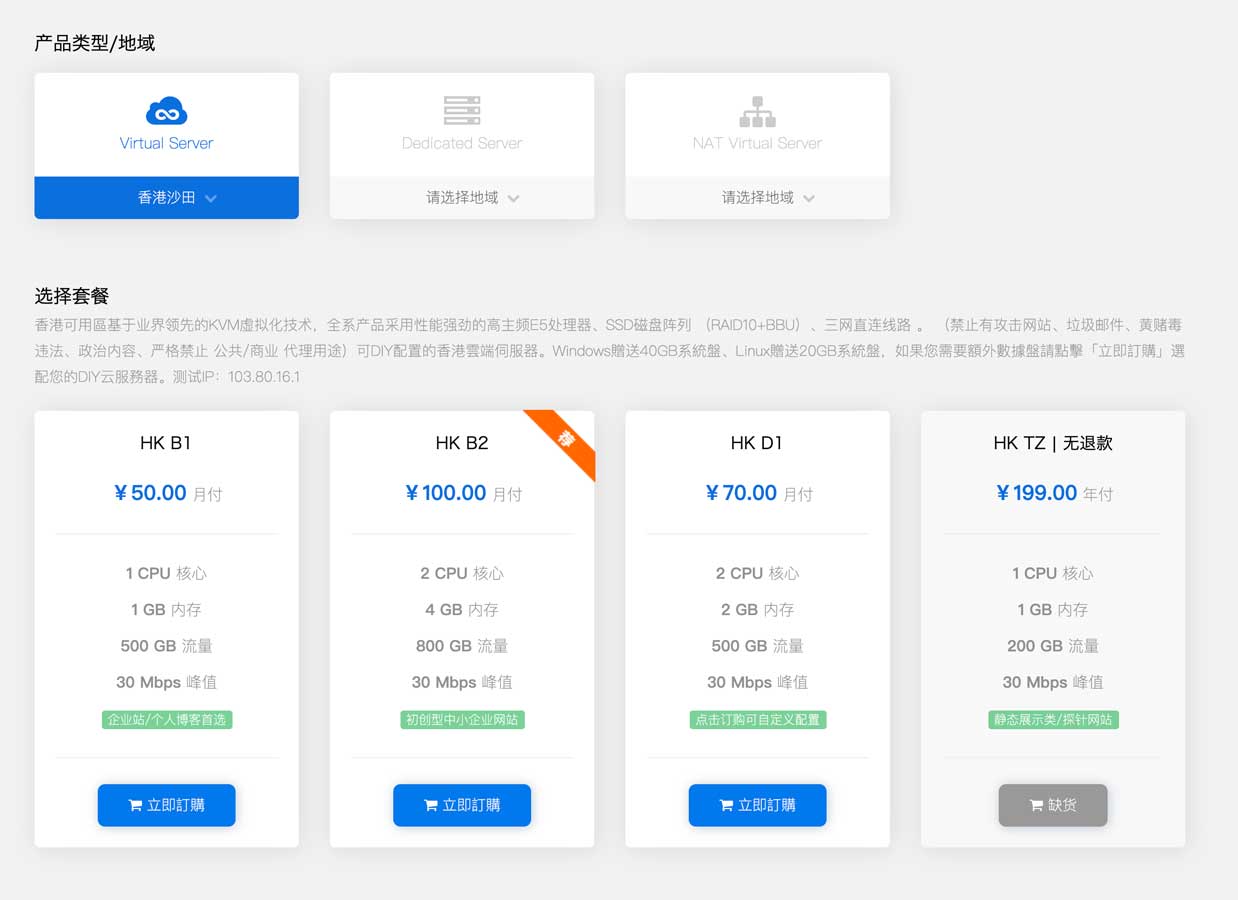
对于只放置一个没人看的博客的服务器来说,500G流量绰绰由于,另外我的静态资源都放在又拍云CDN,所以流量完全够用:
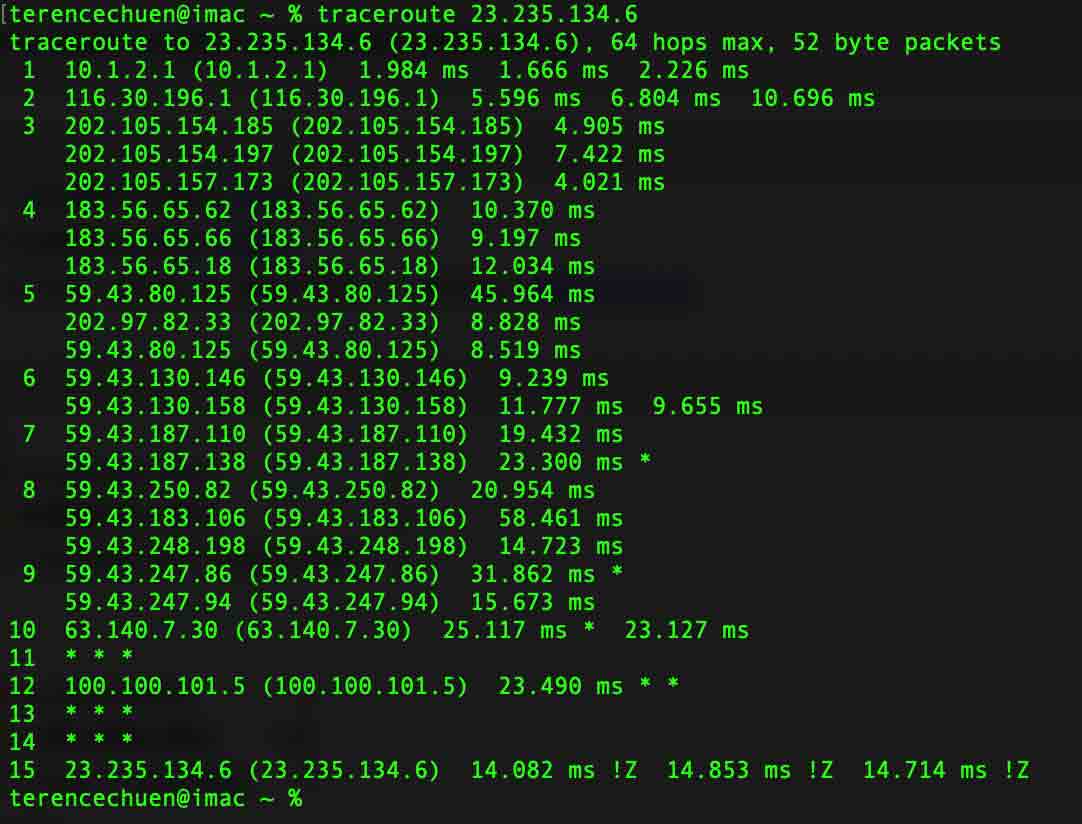
套餐标称带宽30Mbps,因为我只有电信宽带,所以只能测试电信的情况,以下是双向路由追踪:
- 从深圳电信至博客服务器
- 从博客服务器至深圳电信
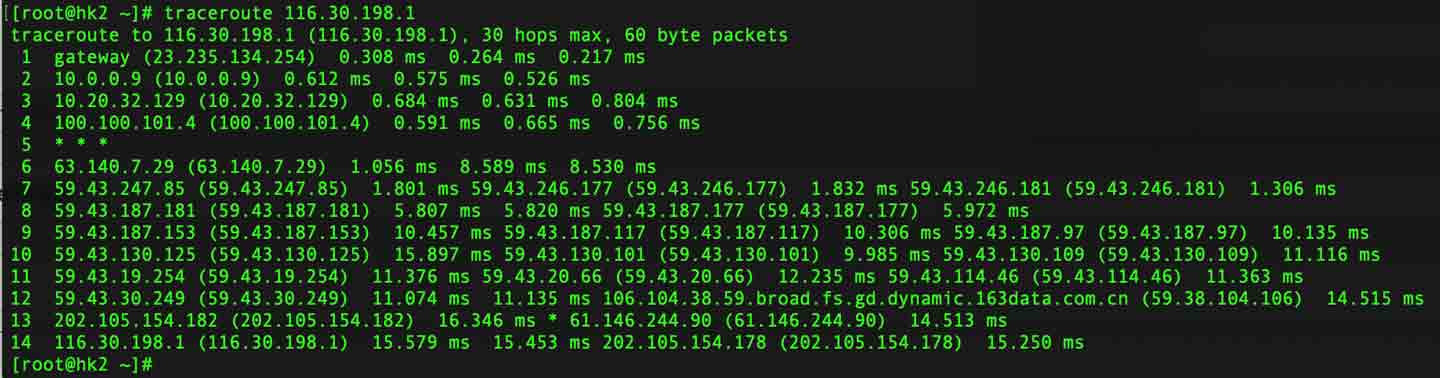
路由没有太大问题,带宽测试如下:
# 广西南宁电信 [root@hk2 ~]# speedtest-cli --server 27810 Retrieving speedtest.net configuration... Testing from Power Line Datacenter (23.235.134.6)... Retrieving speedtest.net server list... Retrieving information for the selected server... Hosted by GX-Telecom (Nanning) [12747.00 km]: 34.128 ms Testing download speed................................................................................ Download: 28.30 Mbit/s Testing upload speed...................................................................................................... Upload: 32.73 Mbit/s # 上海联通 [root@hk2 ~]# speedtest-cli --server 21005 Retrieving speedtest.net configuration... Testing from Power Line Datacenter (23.235.134.6)... Retrieving speedtest.net server list... Retrieving information for the selected server... Hosted by China Unicom (Shanghai) [11329.73 km]: 86.206 ms Testing download speed................................................................................ Download: 24.78 Mbit/s Testing upload speed...................................................................................................... Upload: 10.79 Mbit/s #湖南长沙移动 [root@hk2 ~]# speedtest-cli --server 28491 Retrieving speedtest.net configuration... Testing from Power Line Datacenter (23.235.134.6)... Retrieving speedtest.net server list... Retrieving information for the selected server... Hosted by China Mobile HuNan 5G (ChangSha) [12009.72 km]: 244.321 ms Testing download speed................................................................................ Download: 19.46 Mbit/s Testing upload speed...................................................................................................... Upload: 1.75 Mbit/s # 香港SmarTone [root@hk2 ~]# speedtest-cli --server 19036 Retrieving speedtest.net configuration... Testing from Power Line Datacenter (23.235.134.6)... Retrieving speedtest.net server list... Retrieving information for the selected server... Hosted by SmarTone (Hong Kong) [12552.10 km]: 1680.726 ms Testing download speed............................................................................... .Download: 29.05 Mbit/s Testing upload speed...................................................................................................... Upload: 31.63 Mbit/s
带宽上下行都限制在30Mbps,这符合套餐上的标称值,对于月费70元的vps来说,简直是超值。这个带宽与我用Pachosting时一致,但Pachosting在会对长时间占用带宽的服务器作出QOS限制,可用速率非常低,需要24小时甚至下个付费周期才能恢复,这部分内容可以浏览我此前的文章。不知道这个规则会不会沿用到LayerStack。
因为我博客架构的关系,对磁盘IO的需求不高,这个节点是一个边缘节点,计算节点并不在上面,为了进一步比对,以下是基于dd的IO测试:
[root@hk2 tmp]# dd bs=1M count=4096 if=/dev/zero of=4gb-1.test conv=fdatasync 记录了4096+0 的读入 记录了4096+0 的写出 4294967296字节(4.3 GB)已复制,28.8436 秒,149 MB/秒
磁盘的持续写性能一般,其他IO测试并未进行,一下是CPU信息:
[root@hk2 tmp]# cat /proc/cpuinfo processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 62 model name : Intel(R) Xeon(R) CPU E5-2697 v2 @ 2.70GHz stepping : 4 microcode : 0x1 cpu MHz : 2699.998 cache size : 4096 KB physical id : 0 siblings : 2 core id : 0 cpu cores : 2 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl eagerfpu pni pclmulqdq ssse3 cx16 pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm ssbd ibrs ibpb stibp fsgsbase tsc_adjust smep erms xsaveopt spec_ctrl intel_stibp bogomips : 5399.99 clflush size : 64 cache_alignment : 64 address sizes : 46 bits physical, 48 bits virtual power management: processor : 1 vendor_id : GenuineIntel cpu family : 6 model : 62 model name : Intel(R) Xeon(R) CPU E5-2697 v2 @ 2.70GHz stepping : 4 microcode : 0x1 cpu MHz : 2699.998 cache size : 4096 KB physical id : 0 siblings : 2 core id : 1 cpu cores : 2 apicid : 1 initial apicid : 1 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl eagerfpu pni pclmulqdq ssse3 cx16 pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm ssbd ibrs ibpb stibp fsgsbase tsc_adjust smep erms xsaveopt spec_ctrl intel_stibp bogomips : 5399.99 clflush size : 64 cache_alignment : 64 address sizes : 46 bits physical, 48 bits virtual power management:
以下是Unix Benchmark结果:
========================================================================
BYTE UNIX Benchmarks (Version 5.1.3)
System: hk2: GNU/Linux
OS: GNU/Linux -- 3.10.0-957.10.1.el7.x86_64 -- #1 SMP Mon Mar 18 15:06:45 UTC 2019
Machine: x86_64 (x86_64)
Language: en_US.utf8 (charmap="UTF-8", collate="UTF-8")
CPU 0: Intel(R) Xeon(R) CPU E5-2697 v2 @ 2.70GHz (5400.0 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET
CPU 1: Intel(R) Xeon(R) CPU E5-2697 v2 @ 2.70GHz (5400.0 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET
15:05:35 up 8 days, 18:30, 1 user, load average: 0.15, 0.17, 0.12; runlevel 2020-03-20
------------------------------------------------------------------------
Benchmark Run: 六 3月 28 2020 15:05:35 - 15:33:58
2 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 20102028.6 lps (10.0 s, 7 samples)
Double-Precision Whetstone 2739.7 MWIPS (10.7 s, 7 samples)
Execl Throughput 641.6 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 193743.7 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 56291.8 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 509656.2 KBps (30.0 s, 2 samples)
Pipe Throughput 397490.8 lps (10.1 s, 7 samples)
Pipe-based Context Switching 64490.2 lps (10.0 s, 7 samples)
Process Creation 2313.8 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 2034.4 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 415.1 lpm (60.1 s, 2 samples)
System Call Overhead 439755.4 lps (10.1 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 20102028.6 1722.5
Double-Precision Whetstone 55.0 2739.7 498.1
Execl Throughput 43.0 641.6 149.2
File Copy 1024 bufsize 2000 maxblocks 3960.0 193743.7 489.3
File Copy 256 bufsize 500 maxblocks 1655.0 56291.8 340.1
File Copy 4096 bufsize 8000 maxblocks 5800.0 509656.2 878.7
Pipe Throughput 12440.0 397490.8 319.5
Pipe-based Context Switching 4000.0 64490.2 161.2
Process Creation 126.0 2313.8 183.6
Shell Scripts (1 concurrent) 42.4 2034.4 479.8
Shell Scripts (8 concurrent) 6.0 415.1 691.9
System Call Overhead 15000.0 439755.4 293.2
========
System Benchmarks Index Score 400.9
------------------------------------------------------------------------
Benchmark Run: 六 3月 28 2020 15:33:58 - 16:02:27
2 CPUs in system; running 2 parallel copies of tests
Dhrystone 2 using register variables 31976771.2 lps (10.0 s, 7 samples)
Double-Precision Whetstone 4711.1 MWIPS (10.5 s, 7 samples)
Execl Throughput 1919.9 lps (29.8 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 272344.7 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 72736.2 KBps (30.1 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 749570.9 KBps (30.0 s, 2 samples)
Pipe Throughput 679092.3 lps (10.0 s, 7 samples)
Pipe-based Context Switching 96455.9 lps (10.0 s, 7 samples)
Process Creation 5883.5 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 3164.9 lpm (60.1 s, 2 samples)
Shell Scripts (8 concurrent) 433.2 lpm (60.1 s, 2 samples)
System Call Overhead 687154.2 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 31976771.2 2740.1
Double-Precision Whetstone 55.0 4711.1 856.6
Execl Throughput 43.0 1919.9 446.5
File Copy 1024 bufsize 2000 maxblocks 3960.0 272344.7 687.7
File Copy 256 bufsize 500 maxblocks 1655.0 72736.2 439.5
File Copy 4096 bufsize 8000 maxblocks 5800.0 749570.9 1292.4
Pipe Throughput 12440.0 679092.3 545.9
Pipe-based Context Switching 4000.0 96455.9 241.1
Process Creation 126.0 5883.5 466.9
Shell Scripts (1 concurrent) 42.4 3164.9 746.4
Shell Scripts (8 concurrent) 6.0 433.2 722.0
System Call Overhead 15000.0 687154.2 458.1
========
System Benchmarks Index Score 654.8
按这个结果来看,并不适合做运算,如果有需要,建议购买UOvZ的独立服务器,同样价廉物美。
0x04 结语
我博客的架构也有少许变化,因为计算节点是通过UOvZ与边缘节点互联互通,较之前提升了回源的速度,使用交互功能时的相应速度更高,另外连接至OVH高防节点速度的提升也使得故障转移的速度更快。
希望UOvZ能一直保持这些优势,使用一段时间觉得没问题,我愿意长时间使用并大力推荐:
此外,我的LayerStack在2020年5月19日才到期,目前处于闲置状态,上面部署了LookingGlass服务,有需要的朋友可以去测试LayerStack的网络性能。





















