0x01 前言
一直以来我都对logstash插件的性能存在疑惑,究竟日志量达到多大的时候会出现瓶颈?类似的问题在我的群里也多次出现。因此,我决定进行一系列的测试。
这个测试项目本应在7月底完成并发布的,但因诸多因素导致未能实现。而在这周,我尝试继续该测试计划。测试工作虽然已经完成,但是测试的结果不具权威性,因为有诸多因素影响着测试结果。最终,我决定不公布测试结果,只针对测试环境的部署和配置、相关软件的应用和数据监控等内容撰写文章以供参考。
0x02 虚拟机环境
elatsic stack各个组件均部署在独立的虚拟机中,这是为了避免争抢资源,而且需要部署elasticsearch、logstash和kibana。除了被测的loastash,其余两个组件主要用于监控,因为需要用到x-pack对logstash的监控。
而虚拟机所用的硬盘位SSD,虚拟磁盘模式为厚置备置零,大小均为20GB;vCPU为2核心,全部预留并限制在4Ghz;内存全部锁定并限制在2GB;数据则通过esxi内部虚拟交换机进行交换。
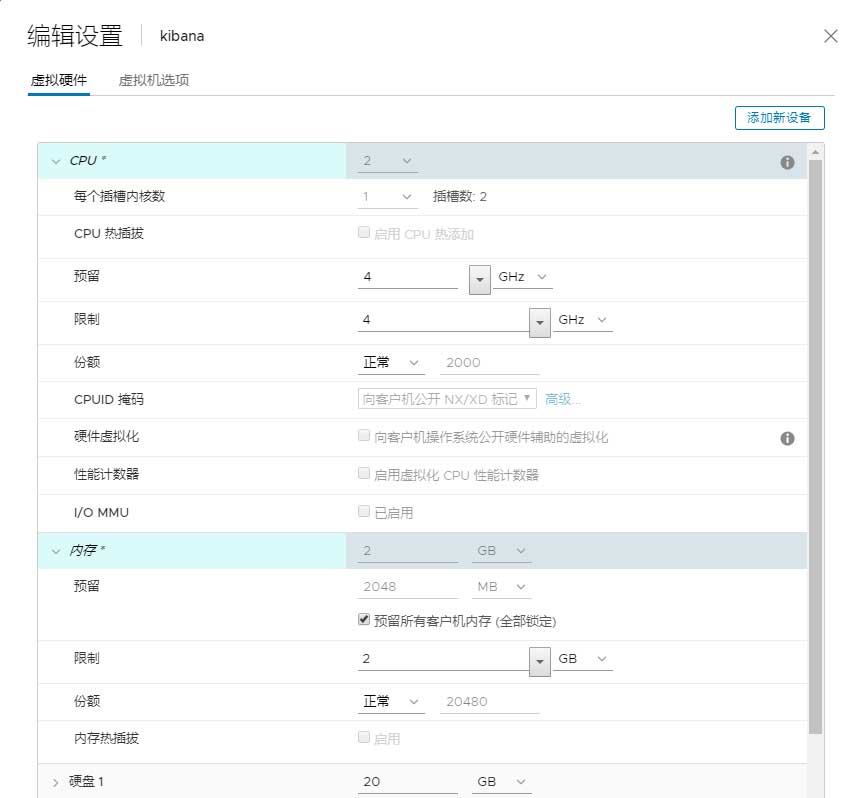
为了尽可能减少资源争抢情况的发生,需要针对CPU和内存做出锁定的配置;虚拟磁盘如果使用厚置备延迟置零或者精简置备的模式,有可能在IO上产生瓶颈,从而影响测试结果。
0x03 elatsic stack
我所使用的elatsic stack套件为最新的版本,均为7.3.1-1,测试所用的系统信息如下:
[root@kibana-t1 ~]# lsb_release -a LSB Version: :core-4.1-amd64:core-4.1-noarch:cxx-4.1-amd64:cxx-4.1-noarch:desktop-4.1-amd64:desktop-4.1-noarch:languages-4.1-amd64:languages-4.1-noarch:printing-4.1-amd64:printing-4.1-noarch Distributor ID: CentOS Description: CentOS Linux release 7.6.1810 (Core) Release: 7.6.1810 Codename: Core
在这次实验中,logstash是测试的目标,而elasticsearch和kibana仅用于监控,所以这两个组件的配置较为简单。监控需要用到免费的x-pack模块,其实logstash支持通过API调用的形式进行监控,而x-pack模块能结合elasticsearch和kibana提供更直观的可视化视图,所以我这次实验选用这种结构。
分别在三台虚拟机里各安装一个组件,但暂不启动。因为从7.0开始,x-pack的绝大部分功能均免费,而这次实验所用的monitor功能也属免费之列,而且x-pack已经集成在各个组件之中。所以我们只需要启用即可。首先配置elasticsearch:
打开/etc/elasticsearch/elasticsearch.yml文件,并在文件底部添加以下两行:
xpack.security.enabled: false xpack.monitoring.collection.enabled: true
如果使用的是免费版x-pack,第一行可以不添加,因为x-pack的权限控制功能是收费的功能,默认情况下是关闭的。但是需要添加第二行以打开免费的监控数据收集功能,然后启动或重启elasticsearch即可。
因为各个组件不在同一个系统内,还需要确认elasticsearch监听的IP地址非127.0.0.0,也就是localhost,以便其他两个组件通过网络访问elasticsearch的API端口:
network.host: 10.1.1.109 http.port: 9200
请确认以上配置内容以适配你自身的环境,另外,建议在配置文件底部添加以下内容:
http.cors.enabled: true http.cors.allow-origin: "*" action.auto_create_index: +*
0x04 logstash
这次测试主要针对grok这个插件,其实也可以延伸到其他插件,只需要修改配置文件即可。而我的测试主要模拟两种日志情况,测试的目的是获取以下数据:
- 日志生成程序每秒钟发出的日志量
- logstash每秒接收到的日志量
- grok插件每秒处理的日志量
- grok插件的事件延迟值
通过调整日志生成程序每秒发出日志的数量即可模拟不同量级对logstash的压力,但这里会有个问题:日志的复杂程度也会影响性能,所以在我这次测试中,均使用同样的日志格式和内容。而日志生成程序每秒钟发出的日志量分为1千条/s、5万条/s、50万条/s和100万条/s四个级别,分别在以下2种日志类型中进行测试:
- 禁用grok插件,日志为json格式,可交由elasticsearch直接解析;
- 启用grok插件,日志为我自定义的日志格式。
相关的配置文件如下:
input {
tcp {
port => 5014
}
}
filter {
grok {
match => { "message" => "%{IPORHOST:client_ip} - (%{GREEDYDATA:auth}|-) \[%{HTTPDATE:timestamp}\] \"(%{WORD:verb} %{GREEDYDATA:request} HTTP/%{NUMBER:http_version}|%{GREEDYDATA:request})\" (%{IPORHOST:domain}|%{URIHOST:domain}|-) %{NUMBER:response} %{NUMBER:bytes} %{QS:referrer} %{QS:ngx_ua} \"(%{IP:x_forword_ip},.*|%{IP:x_forword_ip}|unknown|-)\" (\[|)(%{IP:upstream_host}|%{NOTSPACE:upstream_host}|-)(\]|)(\:%{NUMBER:upstream_port}|) (%{NUMBER:upstream_response}|-) (%{WORD:upstream_cache_status}|-) \"%{NOTSPACE:upstream_content_type}(; charset\=%{NOTSPACE:upstream_content_charset}|)\" (%{NUMBER:upstream_response_time}|-) > %{NUMBER:request_time}" }
}
}
output {
}
为了避免logstash与elasticsearch之间的连接问题对测试结果产生影响,output部分不作配置。
默认情况下,x-pack的监控功能在logstash中是禁用的,所以需要将配置文件中的以下内容做出修改并取消注释:
xpack.monitoring.enabled: true xpack.monitoring.elasticsearch.hosts: ["http://10.1.1.109:9200/"] xpack.monitoring.collection.interval: 3s xpack.monitoring.collection.pipeline.details.enabled: true
完成修改后即可启动或重启logstash。
0x05 kibana
kibana的配置比较简单,只需要修改以下内容即可:
server.port: 5601 server.host: "0.0.0.0" elasticsearch.hosts: ["http://10.1.1.109:9200"]
如果可以,建议将默认的5601端口修改为80,这样就不需要手动在浏览器地址栏里添加端口。
重启后打开kibana界面,并进入集群监控界面:
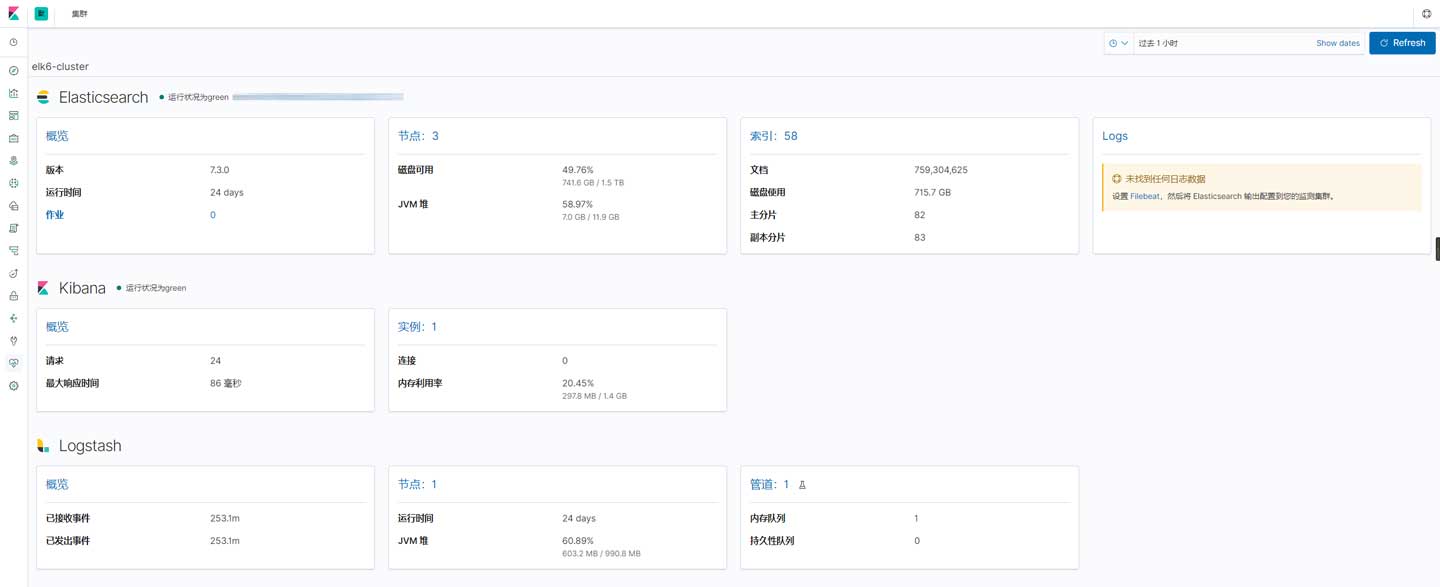
然后进入logstash的管道监控,并选择main管道:

通过单击特定的插件即可获取上一章节中所说的数据。
0x06 loggen
日志的生成与发送我使用loggen这一款开源软件,来源于syslog-ng:
[root@loggen ~]# yum info syslog-ng
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
Installed Packages
Name : syslog-ng
Arch : x86_64
Version : 3.5.6
Release : 3.el7
Size : 1.6 M
Repo : installed
From repo : epel
Summary : Next-generation syslog server
URL : http://www.balabit.com/network-security/syslog-ng
License : GPLv2+
Description : syslog-ng is an enhanced log daemon, supporting a wide range of input and
: output methods: syslog, unstructured text, message queues, databases (SQL
: and NoSQL alike) and more.
:
: Key features:
:
: * receive and send RFC3164 and RFC5424 style syslog messages
: * work with any kind of unstructured data
: * receive and send JSON formatted messages
: * classify and structure logs with builtin parsers (csv-parser(),
: db-parser(), ...)
: * normalize, crunch and process logs as they flow through the system
: * hand on messages for further processing using message queues (like
: AMQP), files or databases (like PostgreSQL or MongoDB).
它支持从文件内读取日志条目并发送,也支持虚构syslog格式的日志。而我使用的命令如下:
loggen -r 50000 -d --file-read-file=/root/temp/access.log -l -i -I 600 10.1.1.123 5014
- -r:日志发送速率
- -d:不修改日志格式,默认情况下会将文件内的条目修改为syslog格式
- –file-read-file:日志文件路径
- -l:循环读取文件
- -i:使用网络传输,支持TCP和UDP
- -I:执行时间
- IP地址:目标IP
- 端口:目标端口
上述所说的两种日志类型,只需分别将日志写入单独的文件,而后修改loggen读取文件的路径即可。
0x07 结语
非常可惜,我没有合适的测试环境,本次测试出来的数据并不可靠,未能在本文中发布。但在实际测试中可以确认grok等插件会让logstash的性能下降,随着日志量的增大,性能会急剧下降。尤其是使用了多个插件和多条判断语句的情况,这种情况请参考本文中kibana监控管道的图片。
我还测试了我实际应用的环境,当每秒日志量达到20万的时候出现很明显的延迟,CPU和磁盘IO均出现较高负载的情况,如果有需要,建议部署多个logstash节点并在他们前面增设负载均衡器,在后面也建议增加缓存或队列系统以避免elasticsearch负载过高。












服务器散热风扇的转速")

 测试环境")







