0x01 前言
我的elasticsearch集群在刚建立之初只是想用于测试,所以每个节点只有300G的磁盘空间。但后来用在我自己业务的日志分析,磁盘空间则越来越小,最后不得不计划磁盘扩容的工作。
elasticsearch磁盘扩容非常简单,只需要将node中的分片迁移出去,然后从集群中剔除该node,重新安装系统和部署elasticsearch后即可重新加入集群。
为什么要那么麻烦?因为我家里服务器的资源有限,而且虚拟机的mac地址已经配置到路由器中,更改起来比较麻烦,所以只能通过该办法实现扩容。
0x02 准备
在开始之前得先确认集群的一些情况,首先要确认现在集群中节点的数量,比如我的:
GET /_cat/nodes

如果你有安装x-pack,也可以通过monitor查看相关状态:
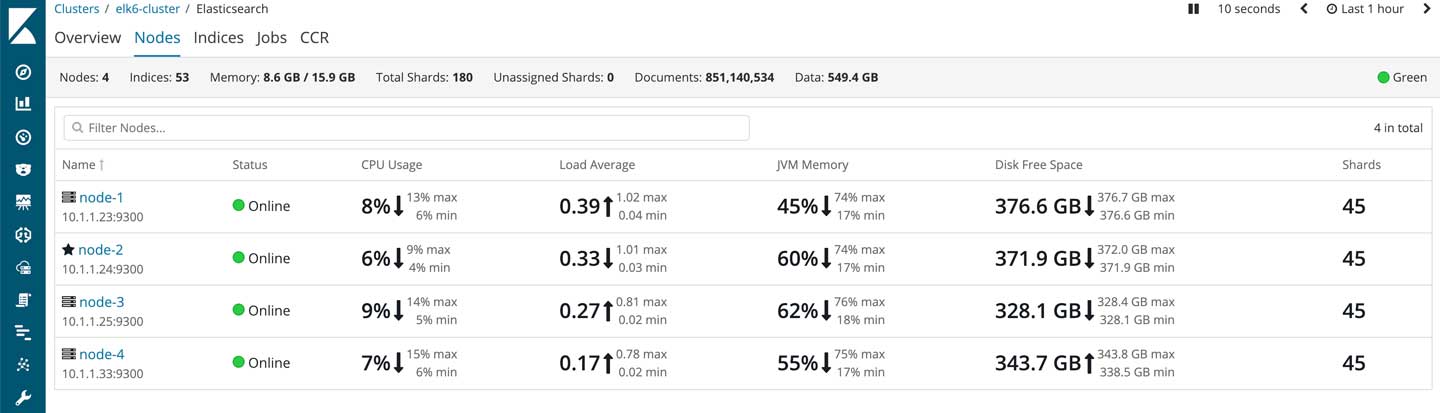
默认情况下,集群各个节点中的分片数量都是相等的,有且只有一个master node。如果你的集群不可中断,则不建议参考本文进行扩容工作。为此,建议参考以下文档进行配置:
简单来说,elasticsearch为了防止脑裂情况的发生而导致数据丢失,建议使用以下公式计算最小master node的数量:
(master_eligible_nodes / 2) + 1
比如我的集群中有4个节点,则master node建议为2个。在此情况下,发生脑裂的几率会大大降低。
还有一个需要注意的点是:在扩容的过程中,请确保节点数不要小于扩容前的节点数。为此,建议大家在开始前添加一个node,扩容结束后删除即可。
0x03 迁移、扩容与加入
其实我的elasticsearch集群在一开始只有3个节点,其中一个为master,上图中的node4其实是扩容完成后保留下来的。
数据迁移与扩容得一个一个节点操作,切勿同时操作多个节点。首先明确需要迁移的节点的IP地址,然后在kibana的console中执行以下命令:
PUT _cluster/settings
{
"transient" : {
"cluster.routing.allocation.exclude._ip" : "10.0.0.1"
}
}
当然,你也可以在master node的系统下执行以下命令:
curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"transient" : {
"cluster.routing.allocation.exclude._ip" : "10.0.0.1"
}
}
'
执行以上命令后会将10.0.0.1这个IP地址的node从集群中剔除,而该集群中的分片会立即迁移至其他node,直至该node中的分片数量为0。
耐心等待后即可通过以下命令检查node中的分片数量:
GET /_cat/allocation?v
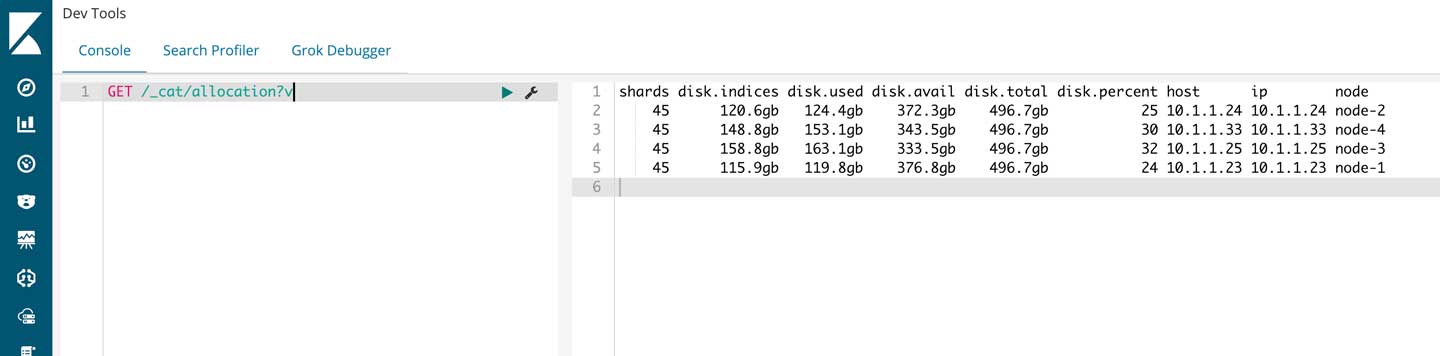
或者在master node中通过curl检查:
curl -X GET "localhost:9200/_cat/allocation?v"
确认分片数量为0后,即可登入到需要扩容节点的系统中停止elasticsearch服务并关机。然后实施重装系统或挂载磁盘等操作,完成后重新启动elasticsearch服务即可。
node重新加入集群后并不会自动同步分片,因为上面已经将它的IP剔除了,此时需要执行以下命令将其加入其中:
# kibana console
PUT _cluster/settings
{
"transient" : {
"cluster.routing.allocation.exclude._ip" : "10.0.0.1"
}
}
# curl
curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"transient" : {
"cluster.routing.allocation.include._ip" : "10.0.0.*"
}
}
'
同步完成后再重复以上步骤即可。
最后需要提醒的是,如果你只有一个master node,当集群中的node小于3时,会导致集群脑裂,从而使elasticsearch拒绝服务。
0x04 解语
这次扩容花掉了我一整天的时间,因为计算和存储资源的匮乏限制了我集群中node的数量,而elasticsearch倒腾数据需要的时间又非常长,所以在有极其庞大数据的时候建议增加node数量,可以同时扩容多个node。
当有一个node从集群中离线时会出现Unassigned Shards,直至新node加入并恢复(recovery),而默认情况下,恢复的速度被限制在40mbps。如果你的网络和磁盘IO都支持更高的速度,则可以通过以下命令对该参数进行调整:
# kibana console
PUT /_cluster/settings
{
"persistent" : {
"indices.recovery.max_bytes_per_sec" : "100mb"
}
}
# curl
curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"persistent" : {
"indices.recovery.max_bytes_per_sec" : "100mb"
}
}
'
















 – pachosting")





