
0x01 前言
最近在试用腾讯云的CDN,我CN的域名已经解析到腾讯云的CDN。如果你正在访问enginx\.cn,那么你目前连接的应该是腾讯云CDN的某个节点;如果目前访问的域名是enginx\.net,则是我博客的源服务器。
为了方便了解访客的具体情况,我习惯用elasticstack分析日志并生成实时图表。正好藉此机会,我详细地描述如何编写logstash的配置文件与grok的语法。
0x02 准备
首先是腾讯云CDN的日志,我在这几天写了一个python脚本,实现自动下载日志的功能,这部分内容将在日后的文章中详细说明。
腾讯云CDN的日志格式如下:
20180203174659 113.116.49.122 enginx.cn /%e4%b8%8e%e6%88%91%e8%81%94%e7%b3%bb 16400 4 2 200 https://enginx.cn/2018/01/21/%e8%af%a6%e8%a7%a3%e5%ae%89%e8%a3%85%e9%85%8d%e7%bd%aeelastic-stack-6%e5%b9%b6%e5%88%86%e6%9e%90nginx%e6%97%a5%e5%bf%97.html 675 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36" "(null)" GET HTTPS hit
各个字段的意义可以在腾讯云的知识库中找到:
在实际的日志中我并没有找到“地域映射”的相关字段,这可能是产品迭代的时候没有更新知识库导致的,这部分先忽略。
然后是“省份映射”与“运营商映射”这两个字段的内容需要做文本匹配与替换,这在我之前分析的日志里没有遇到的。
最后需要一个配置好的elasticstack服务,具体配置方法可以参考以下文章:
0x03 输入与输出
0x03.1 输入
因为腾讯云CDN的日志是以文本文档保存的,所以我用filebeat读取并传送至logstash,那么输入的配置文件如下:
input {
beats {
port => 5016
}
}
以上配置文件监听TCP 5016端口作为best的输入途径。如果需要加密,则配置文件如下:
input {
beats {
port => 5015
ssl => true
ssl_certificate_authorities => ["/etc/logstash/elk_server_crt/ca.crt"]
ssl_certificate => "/etc/logstash/elk_server_crt/server.crt"
ssl_key => "/etc/logstash/elk_server_crt/server.key"
ssl_verify_mode => "force_peer"
}
}
input的方法有许多种,具体请参考官方说明:
为了方便区分和修改配置文件,建议将logstash的配置文件分配一个固定的命名格式,例如我的:
[root@logstash6-node1 ~]# ll -lh /etc/logstash/conf.d/ total 44K -rw-r--r-- 1 root root 121 Dec 11 16:32 00-5014.conf -rw-r--r-- 1 root root 290 Dec 11 16:32 01-5015.conf -rw-r--r-- 1 root root 41 Dec 11 16:32 02-5016.conf -rw-r--r-- 1 root root 169 Dec 11 16:32 03-5017.conf -rw-r--r-- 1 root root 3.3K Dec 11 16:33 10-nginx-fliter.conf -rw-r--r-- 1 root root 591 Dec 11 16:35 11-cdn-fliter.conf -rw-r--r-- 1 root root 774 Dec 11 16:35 12-dhcp-fliter.conf -rw-r--r-- 1 root root 462 Dec 11 16:35 13-snort-fliter.conf -rw-r--r-- 1 root root 5.0K Jan 29 23:52 14-qcloud-cdn-fliter.conf -rw-r--r-- 1 root root 1.8K Jan 29 23:43 99-output.conf
0x03.2 输出
输出的配置也很简单,例如我的:
[root@logstash6-node1 ~]# cat /etc/logstash/conf.d/99-output.conf
output {
if "server_ngx_access_log" in [tags] {
elasticsearch {
hosts => ["es6-node1.t.com:9200", "es6-node2.t.com:9200", "es6-node3.t.com:9200"]
manage_template => false
index => "public-ngx-alias"
}
} else if "tencent_cdn" in [tags] {
elasticsearch {
hosts => ["es6-node1.t.com:9200", "es6-node2.t.com:9200", "es6-node3.t.com:9200"]
manage_template => false
index => "tencent-cdn-%{+YYYY}"
}
} else if "dhcp_log" in [tags] {
elasticsearch {
hosts => ["es6-node1.t.com:9200", "es6-node2.t.com:9200", "es6-node3.t.com:9200"]
manage_template => false
index => "dhcp_log-%{+YYYY}"
}
} else if "snort_log" in [tags] {
elasticsearch {
hosts => ["es6-node1.t.com:9200", "es6-node2.t.com:9200", "es6-node3.t.com:9200"]
manage_template => false
index => "snort-alias"
}
} else if "modsec_audit_log" in [tags] {
elasticsearch {
hosts => ["es6-node1.t.com:9200", "es6-node2.t.com:9200", "es6-node3.t.com:9200"]
manage_template => false
index => "modsec_audit_log-%{+YYYY}"
}
} else if "win32_log" in [tags] {
elasticsearch {
hosts => ["es6-node1.t.com:9200", "es6-node2.t.com:9200", "es6-node3.t.com:9200"]
manage_template => false
index => "win32_log-%{+YYYY}"
}
} else if "qcloud_cdn_log" in [tags] {
elasticsearch {
hosts => ["es6-node1.t.com:9200", "es6-node2.t.com:9200", "es6-node3.t.com:9200"]
manage_template => false
index => "qcloud-log_alias"
}
} else {
elasticsearch {
hosts => ["es6-node1.t.com:9200", "es6-node2.t.com:9200", "es6-node3.t.com:9200"]
manage_template => false
index => "log-content-%{+YYYY}"
}
}
}
如果logstash集群同时处理许多种日志,这时候就需要通过if..else..对日志进行分门别类地输出至elasticsearch。
如上面的配置文件,我分别对tags标签里的内容进行判断,如果包含我设定的内容,则投放至指定的索引中;而hosts中则填写了3个elasticsearch节点,可以实现负载均衡。
logstash output插件也支持许多种输出方式,具体可以参考官方文档:
- Logstash Reference [6.1] » Output plugins
- Logstash Reference [6.1] » Output plugins » Elasticsearch output plugin
0x04 过滤器
filter plugin是logstash的核心,包含许多过滤器,而分析腾讯CDN需要用到以下4种:
- grok:grok通过匹配模板将非结构化的数据转化为结构化的数据
- geoip:通过Maxmind GeoLite2数据库分析IP数据
- date:用于处理时间内容的字段
- useragent:用于分析user agent的数据
- mutate:用于修改、替换、重命名和修改字段或字段中的内容
其他的过滤器可以参考官方文档:
0x04.1 grok
首先通过grok分析腾讯CDN的日志:
20180203174659 113.116.49.122 enginx.cn /%e4%b8%8e%e6%88%91%e8%81%94%e7%b3%bb 16400 4 2 200 https://enginx.cn/2018/01/21/%e8%af%a6%e8%a7%a3%e5%ae%89%e8%a3%85%e9%85%8d%e7%bd%aeelastic-stack-6%e5%b9%b6%e5%88%86%e6%9e%90nginx%e6%97%a5%e5%bf%97.html 675 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36" "(null)" GET HTTPS hit
在编写grok规则的时候,可以通过以下页面参考相关语法:
同时需要打开以下页面进行debug:
还需要了解日志各个字段的意义:
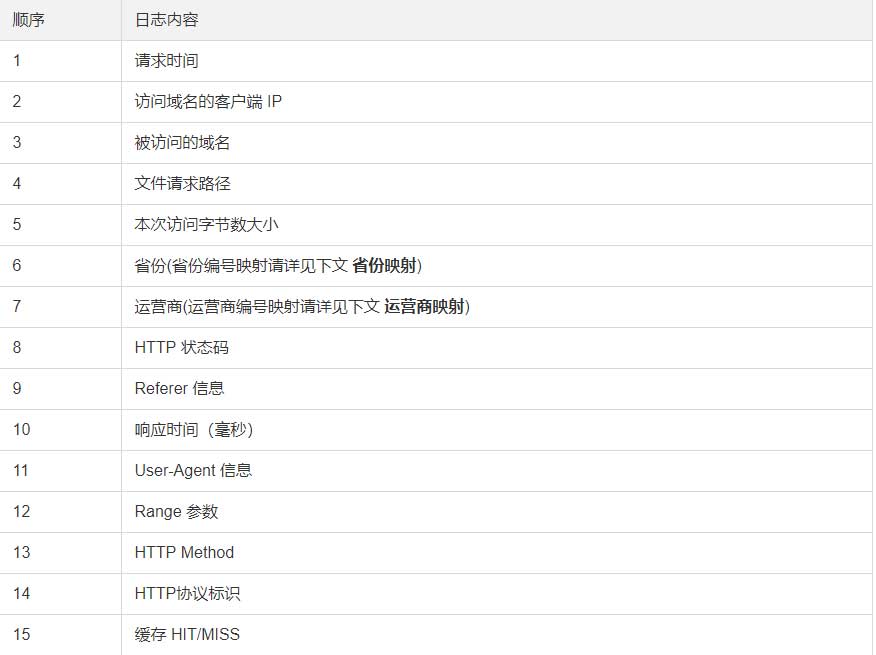
接下来先理解grok的格式,例如需要匹配日志中的第一个字段“请求时间”:
%{NUMBER:timestamp}
以%{}标识为一个字段,花括号内双引号左侧为匹配模板,右侧为自定义的名称。将相关内容放置到Grok Debugger中进行测试,如果没有错误,则会生成json格式的内容:
{
"timestamp": [
[
"20180203174659"
]
]
}
 再看看匹配GitHub匹配模板中关于NUMBER的描述:
再看看匹配GitHub匹配模板中关于NUMBER的描述:
NUMBER (?:%{BASE10NUM})
可以发现,NUMBER匹配的是10进制的数字,它可以匹配正负数、以及小数。
再来看一个例子:
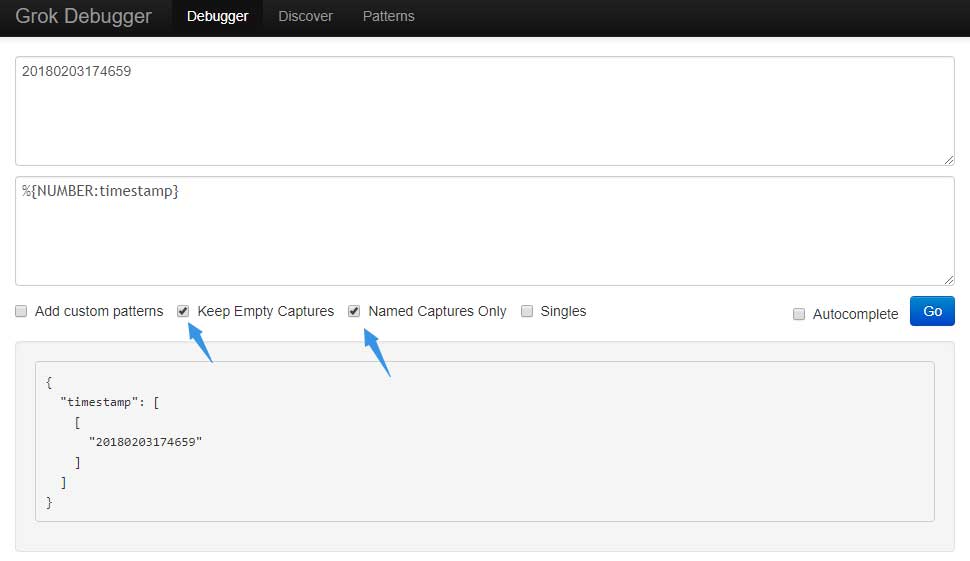
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36"
以上是一个UA字段,因为UA字段内一般会有空格将各部分的内容拆分开,所以会有双引号将UA字段包裹起来,这时候的grok是这样的:
%{QS:agent}
再来看看GitHub的描述:
QS %{QUOTEDSTRING}
QS匹配的是被引号包裹的字符串,那么在Grok Debugger中是这样的:
{
"agent": [
[
""Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36""
]
]
}
 这个QS其实是一种快捷方式,其实还有一种方法:
这个QS其实是一种快捷方式,其实还有一种方法:
\"%{GREEDYDATA:agent}\"
用转义符标识出双引号,然后用GREEDYDATA匹配双引号中的内容,这个GREEDYDATA在GitHub中的描述为:
GREEDYDATA .*
这个正则是匹配一切字符无限次。不过因为UA的两侧各有一个双引号,所以可以使用该匹配模板。
在实际应用中还有可能遇到同一个字段,可能会出现不同类型的内容,例如nginx反向代理upstream可能为空的情况,这时候可以写成如下结构:
(%{IPORHOST:upstream_host}|-)
用一个括号将规则包裹起来,然后在多个规则之间用“|”符号进行分割,匹配将从左到右进行。
#IPORHOST模板
IPORHOST (?:%{IP}|%{HOSTNAME})
#IP模板
IP (?:%{IPV6}|%{IPV4})
#IPV6与IPV4模板
IPV6 ((([0-9A-Fa-f]{1,4}:){7}([0-9A-Fa-f]{1,4}|:))|(([0-9A-Fa-f]{1,4}:){6}(:[0-9A-Fa-f]{1,4}|((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){5}(((:[0-9A-Fa-f]{1,4}){1,2})|:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){4}(((:[0-9A-Fa-f]{1,4}){1,3})|((:[0-9A-Fa-f]{1,4})?:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){3}(((:[0-9A-Fa-f]{1,4}){1,4})|((:[0-9A-Fa-f]{1,4}){0,2}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){2}(((:[0-9A-Fa-f]{1,4}){1,5})|((:[0-9A-Fa-f]{1,4}){0,3}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){1}(((:[0-9A-Fa-f]{1,4}){1,6})|((:[0-9A-Fa-f]{1,4}){0,4}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(:(((:[0-9A-Fa-f]{1,4}){1,7})|((:[0-9A-Fa-f]{1,4}){0,5}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:)))(%.+)?
IPV4 (?<![0-9])(?:(?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5]))(?![0-9])
#HOSTNAME模板
HOSTNAME \b(?:[0-9A-Za-z][0-9A-Za-z-]{0,62})(?:\.(?:[0-9A-Za-z][0-9A-Za-z-]{0,62}))*(\.?|\b)
IPORHOST可以匹配IP与hostname,而IP又包含IPV4和IPV6,很明显,这些内容的结构都是不同的,但他们又是层层包裹,所以仅适用IPORHOST即可匹配上我们需要的内容。而分隔符右侧的“-”则匹配无upstream的情况,在无upstream的时候,nginx日志中这个字段为空,所以是“-”。
其实grok语法非常简单,模板的存在省去了我们编写正则的麻烦,编写的时候要注意考虑字段中可能产生的文本类型,以便完全匹配。
匹配以上例子日志的完整grok规则如下:
%{NUMBER:timestamp} %{IPORHOST:client_ip} %{IPORHOST:domain} %{NOTSPACE:request} %{NUMBER:bytes} %{NUMBER:province} %{NUMBER:isp} %{NUMBER:response} %{NOTSPACE:referrer} %{NUMBER:response_time} %{QS:agent} %{QS:range} %{WORD:verb} %{NOTSPACE:http_version} %{WORD:cache_status}
这里需要提醒!冒号右侧的内容为自定义的名称,可以根据实际情况进行定义,而左侧的匹配模板则需要参考GitHub上的解释进行使用。
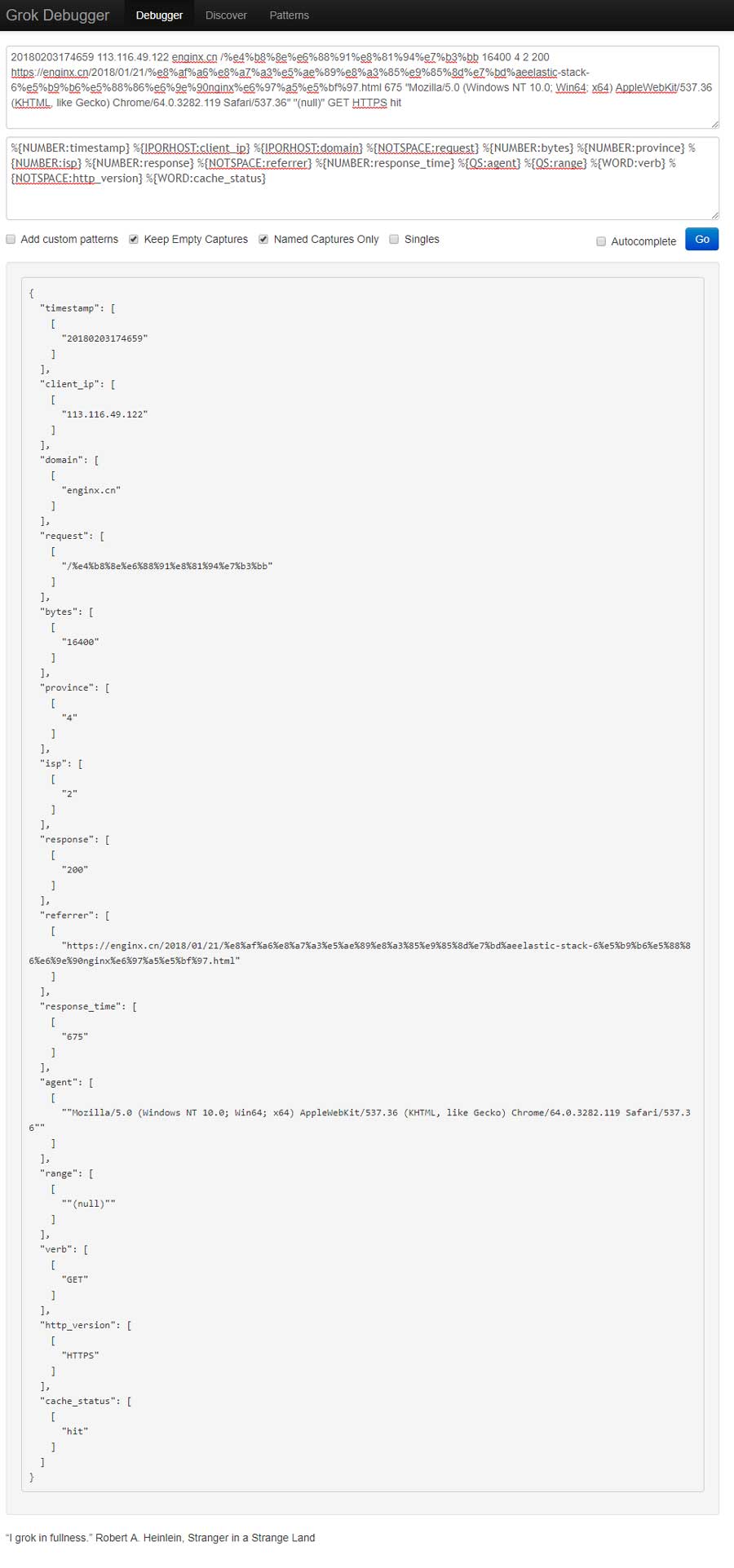
完成grok规则的编写后就可以完成grok配置文件了:
grok {
match => { "message" => "%{NUMBER:timestamp} %{IPORHOST:client_ip} %{IPORHOST:domain} %{NOTSPACE:request} %{NUMBER:bytes} %{NUMBER:province} %{NUMBER:isp} %{NUMBER:response} %{NOTSPACE:referrer} %{NUMBER:response_time} %{QS:agent} %{QS:range} %{WORD:verb} %{NOTSPACE:http_version} %{WORD:cache_status}" }
}
默认情况下,通过best传入的原始内容都放置在message标签内,所以通过match设定,告诉grok使用编写好的规则对message中的内容进行解析。
0x04.2 geoip
geoip是非常有用的一个插件,他可以通过Maxmind GeoLite2数据库中的数据分析IP的具体信息,虽然Maxmind GeoLite2数据库不太准确,但在判断IP所属地还是有很大用途的。
这个插件的使用很简单:
geoip {
source => "client_ip"
}
geoip插件中只需要指定分析数据的来源“source ”就好了,在这里的来源为通过grok分析后的数据,而这个数据的名为“client_ip”。
在这里有一个特别的情况,一般防火墙或路由器的日志都会有来源IP与目标IP,如果使用上述配置,则仅能分析一个IP,这时候需要为json key自定义一个名称:
geoip {
source => "SrcIp"
target => "SrcGeo"
}
geoip {
source => "DstIp"
target => "DstGeo"
}
那么分析出来的json如下:
"SrcGeo": {},
"DstGeo": {
"timezone": "Europe/Amsterdam",
"ip": "37.48.65.151",
"latitude": 52.3824,
"country_name": "Netherlands",
"country_code2": "NL",
"continent_code": "EU",
"country_code3": "NL",
"location": {
"lon": 4.8995,
"lat": 52.3824
},
"longitude": 4.8995
}
因为SrcGeo中的IP为内网IP,所以没有任何信息,如果是公网IP,则与DstGeo中的内容类似。
0x04.3 date
date这个插件是非常重要的!例如腾讯云CDN的日志,统计周期为一小时,而且会延迟10分钟左右,也就是说10:15分前后才能下载9:00-10:00间的数据。
那么会有一个问题,logstash并不知道这日志是一小时前的,如果直接存入elasticsearch,elasticsearch会将接收到该日志的时间作为该日志的生成时间。这个时间差在运维工作中肯定是不允许的。
另外还有一种情况,日志是实时传输的,但是网络传输和分析都需要时间,当存入elasticsearch时可能会有半秒甚至1秒钟的误差,这也是不允许的。
不过我们的日志都是有时间戳,就是为了避免这种问题的产生,而date这个插件也是为了处理时间而存在的。
我们先看看时间在elasticsearch内的格式:
"fields": {
"@timestamp": [
"2018-02-03T09:46:59.000Z"
]
}
然后再看看我们日志中的格式:20180203174659,在实际应用中,日志的内容肯定是尽可能精简,哪怕是一个字符。所以需要对时间进行手动匹配:
date {
match => [ "timestamp" , "YYYYMMddHHmmss" ]
}
和geoip一样,需要使用match提取出经过grok处理后的,自定义名称为“timestamp”的内容,并匹配格式:“YYYYMMddHHmmss”
以下是我nginx日志中的时间格式与匹配规则:
#时间格式
03/Feb/2018:21:35:05 +0800
#匹配规则
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
如果想查找时间格式的语法,请打开以下页面并搜索“More details on the syntax”:
0x04.4 useragent
对于web app来说,UA的解析非常重要,可以为产品后续的发展方向提供有意义的参考价值。
logstash useragent插件的匹配正则请参考以下页面:
而这个插件也无需过多设置:
useragent {
source => "agent"
target => "ua"
}
依然是通过source指定来源,而target则是指定输出json的key名称:
"ua": {
"patch": "3282",
"os": "Windows 10",
"major": "64",
"minor": "0",
"build": "",
"name": "Chrome",
"os_name": "Windows 10",
"device": "Other"
}
0x04.5 mutate
回顾日志,发现日志中包含省份映射和运营商映射,这是以数据为id,不同的id代表不同的内容:
省份映射 22:北京;86:内蒙古;146:山西;1069:河北;1177:天津;119:宁夏;152:陕西;1208:甘肃;1467:青海;1468:新疆;145:黑龙江;1445:吉林;1464:辽宁;2:福建;120:江苏;121:安徽;122:山东;1050:上海;1442:浙江;182:河南;1135:湖北;1465:江西;1466:湖南;118:贵州;153:云南;1051:重庆;1068:四川;1155:西藏;4:广东;173:广西;1441:海南;0:其他;1:港澳台;-1:海外。 运营商映射 2:中国电信;26:中国联通;38:教育网;43:长城宽带;1046:中国移动;3947:中国铁通;-1:海外运营商;0:其他运营商。
可是logstash并不知道对应的关系,这时候就需要mutate这个插件出手了。
这里需要用到if判断,例如grok中isp字段的内容为2,则需要将isp字段中的内容替换为“中国电信”:
if [isp] == "2" {
mutate {
replace => { "isp" => "中国电信" }
}
那么多个映射,则需要用到if…else…:
if [isp] == "-1" {
mutate {
replace => { "isp" => "海外运营商" }
}
} else if [isp] == "0" {
mutate {
replace => { "isp" => "其他运营商" }
}
} else if [isp] == "2" {
mutate {
replace => { "isp" => "中国电信" }
}
} else if [isp] == "26" {
mutate {
replace => { "isp" => "中国联通" }
}
} else if [isp] == "38" {
mutate {
replace => { "isp" => "教育网" }
}
} else if [isp] == "43" {
mutate {
replace => { "isp" => "长城宽带" }
}
} else if [isp] == "1046" {
mutate {
replace => { "isp" => "中国移动" }
}
} else if [isp] == "3947" {
mutate {
replace => { "isp" => "中国铁通" }
}
}
省份的映射配置和运营商的类似。这个插件还有其他功能,具体请参考官方说明:
0x05 完整规则
为了防止类似结构的日志误用该过滤器中的规则,我使用if判断传入日志中的tags标签内是否存在我指定的内容,如果是,则应用该规则,如果不是则pass:
filter {
if "qcloud_cdn_log" in [tags] {
[your rule here]
}
}
那么完整的规则如下:
[root@logstash6-node1 ~]# cat /etc/logstash/conf.d/14-qcloud-cdn-fliter.conf
filter {
if "qcloud_cdn_log" in [tags] {
grok {
match => { "message" => "%{NUMBER:timestamp} %{IPORHOST:client_ip} %{IPORHOST:domain} %{NOTSPACE:request} %{NUMBER:bytes} %{NUMBER:province} %{NUMBER:isp} %{NUMBER:response} %{NOTSPACE:referrer} %{NUMBER:response_time} %{QS:agent} %{QS:range} %{WORD:verb} %{NOTSPACE:http_version} %{WORD:cache_status}" }
}
geoip {
source => "client_ip"
}
date {
match => [ "timestamp" , "YYYYMMddHHmmss" ]
}
useragent {
source => "agent"
target => "ua"
}
if [province] == "-1" {
mutate {
replace => { "province" => "海外" }
}
} else if [province] == "0" {
mutate {
replace => { "province" => "其他" }
}
} else if [province] == "1" {
mutate {
replace => { "province" => "港澳台" }
}
} else if [province] == "22" {
mutate {
replace => { "province" => "北京" }
}
} else if [province] == "86" {
mutate {
replace => { "province" => "内蒙古" }
}
} else if [province] == "146" {
mutate {
replace => { "province" => "山西" }
}
} else if [province] == "1069" {
mutate {
replace => { "province" => "河北" }
}
} else if [province] == "1177" {
mutate {
replace => { "province" => "天津" }
}
} else if [province] == "119" {
mutate {
replace => { "province" => "宁夏" }
}
} else if [province] == "152" {
mutate {
replace => { "province" => "陕西" }
}
} else if [province] == "1208" {
mutate {
replace => { "province" => "甘肃" }
}
} else if [province] == "1467" {
mutate {
replace => { "province" => "青海" }
}
} else if [province] == "1468" {
mutate {
replace => { "province" => "新疆" }
}
} else if [province] == "145" {
mutate {
replace => { "province" => "黑龙江" }
}
} else if [province] == "1445" {
mutate {
replace => { "province" => "吉林" }
}
} else if [province] == "1464" {
mutate {
replace => { "province" => "辽宁" }
}
} else if [province] == "2" {
mutate {
replace => { "province" => "福建" }
}
} else if [province] == "120" {
mutate {
replace => { "province" => "江苏" }
}
} else if [province] == "121" {
mutate {
replace => { "province" => "安徽" }
}
} else if [province] == "121" {
mutate {
replace => { "province" => "山东" }
}
} else if [province] == "1050" {
mutate {
replace => { "province" => "上海" }
}
} else if [province] == "1442" {
mutate {
replace => { "province" => "浙江" }
}
} else if [province] == "182" {
mutate {
replace => { "province" => "河南" }
}
} else if [province] == "1135" {
mutate {
replace => { "province" => "湖北" }
}
} else if [province] == "1465" {
mutate {
replace => { "province" => "江西" }
}
} else if [province] == "1466" {
mutate {
replace => { "province" => "湖南" }
}
} else if [province] == "118" {
mutate {
replace => { "province" => "贵州" }
}
} else if [province] == "153" {
mutate {
replace => { "province" => "云南" }
}
} else if [province] == "1051" {
mutate {
replace => { "province" => "重庆" }
}
} else if [province] == "1068" {
mutate {
replace => { "province" => "四川" }
}
} else if [province] == "1155" {
mutate {
replace => { "province" => "西藏" }
}
} else if [province] == "4" {
mutate {
replace => { "province" => "广东" }
}
} else if [province] == "173" {
mutate {
replace => { "province" => "广西" }
}
} else if [province] == "1441" {
mutate {
replace => { "province" => "海南" }
}
} else if [province] == "121" {
mutate {
replace => { "province" => "安徽" }
}
}
if [isp] == "-1" {
mutate {
replace => { "isp" => "海外运营商" }
}
} else if [isp] == "0" {
mutate {
replace => { "isp" => "其他运营商" }
}
} else if [isp] == "2" {
mutate {
replace => { "isp" => "中国电信" }
}
} else if [isp] == "26" {
mutate {
replace => { "isp" => "中国联通" }
}
} else if [isp] == "38" {
mutate {
replace => { "isp" => "教育网" }
}
} else if [isp] == "43" {
mutate {
replace => { "isp" => "长城宽带" }
}
} else if [isp] == "1046" {
mutate {
replace => { "isp" => "中国移动" }
}
} else if [isp] == "3947" {
mutate {
replace => { "isp" => "中国铁通" }
}
}
}
}
0x06 结语
logstash是一款很重要的软件,担任着分析日志的重任,可配置的内容非常多,几乎与elasticsearch一样复杂,需要花点心思去学习。






















