
0x01 前言
本来今天想写设置kibana 6可视化图表相关的文章,可是有些需要注意的问题还是要做个记录。
0x02 索引
kibana的数据需要从elasticsearch中读取,而读取需要通过index,也就是索引来区分不同的数据集。
在Management中找到Index Patterns,点击进去可以看到类似以下图片中的界面:
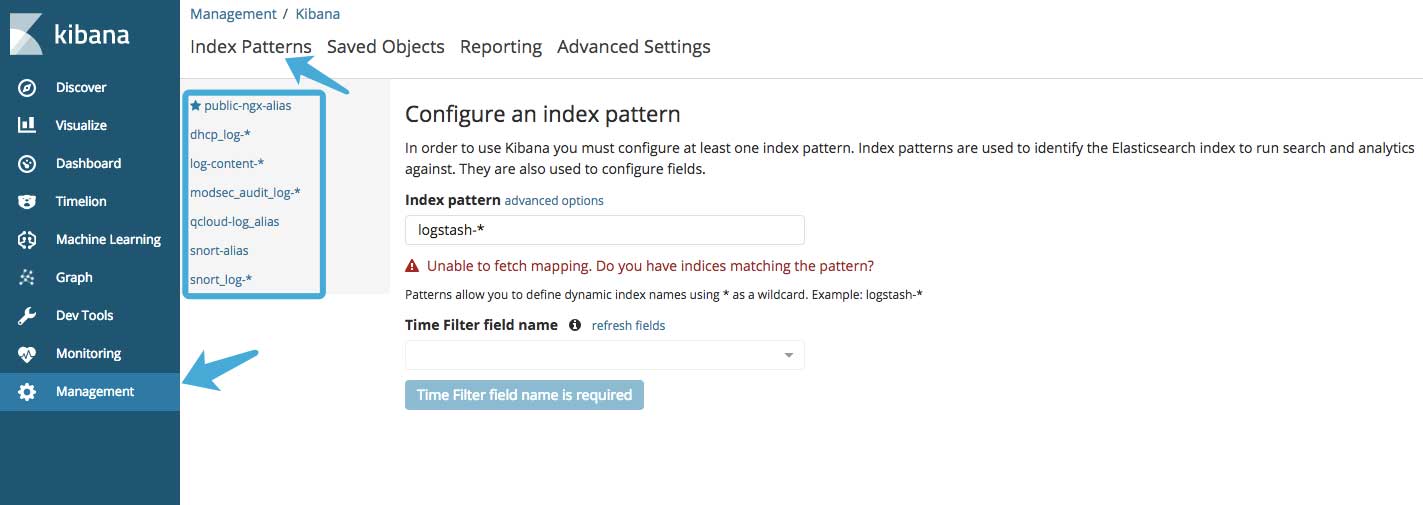
如果kibana是新安装的,那么蓝色框框内应该是没有内容的。
点击页面上的Create Index Pattern按钮添加索引至kibana:
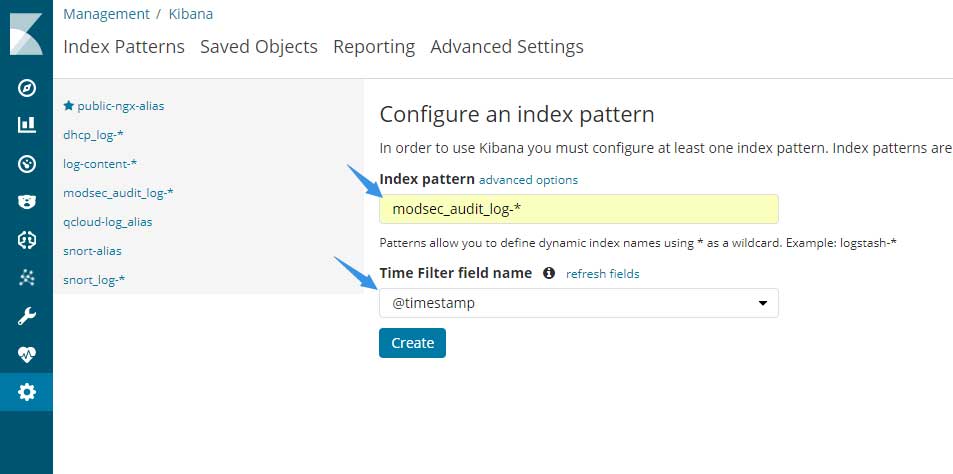
在Index pattern输入框中输入索引的名称,这里要注意:如果你的索引是按一定时间自动创建的,这时候可以使用通配符匹配上所有索引,例如图中的:
- modsec_audit_log-*
这是为了匹配按月生成的索引格式:
- modsec_audit_log-2017-12
- modsec_audit_log-2018-01
- modsec_audit_log-2018-02
- … …
如果你的索引使用固定名称或者需要引入一个索引别名,则可以输入一个完整的名称,如图中的:
- qcloud-log_alias
- public-ngx-alias
- snort-alias
对于索引别名相关的知识,可以参考以下文章:
如果索引存在,那么在Time Filter field name选项框中应该会默然选中@timestemp这个选项。在kibana中,默认通过时间戳来排序。
如果将日志存入elasticsearch的时候没有指定@timestamp这个字段的内容,则elasticsearch会为该日志分配接收到该日志时的时间为@timestamp的值。
如果值错误或删掉该值,那么会有很奇怪的事情发生:
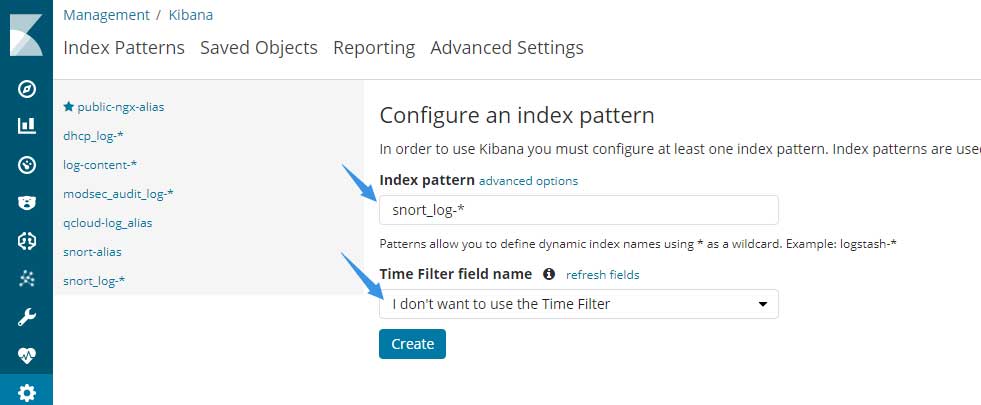
首先在Time Filter field name只会剩下图中的一个选项,当然,在@timestamp字段正常的情况下,也可以手动选择该选项。
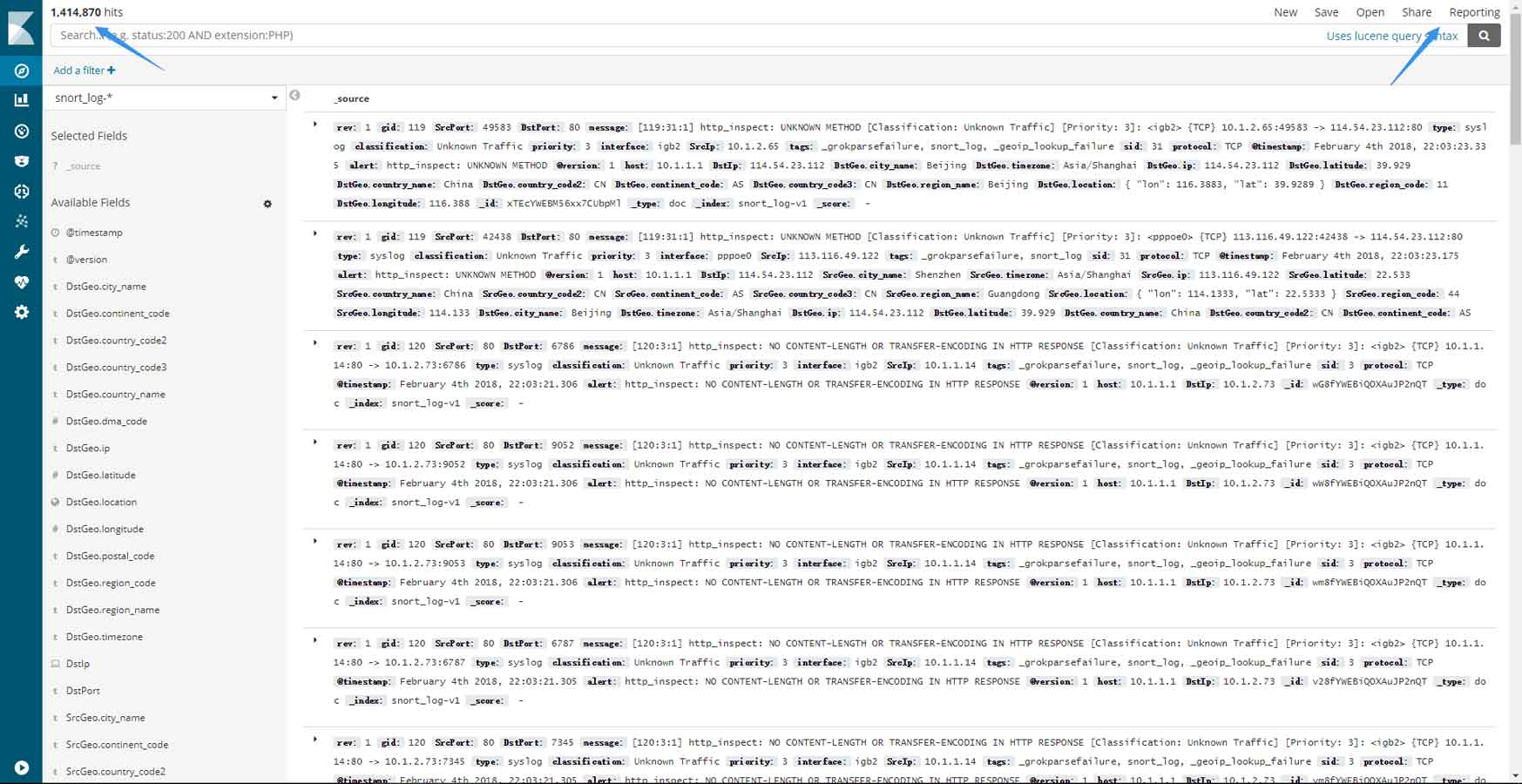
添加完成后,在discover页面中查看该索引,会发现该索引下所有的条目都被列出来了,而且无法通过时间去筛选,也无法自动刷新等一系列功能。当然,可视化图表也是受限的,因为无法判断日志条目的具体时间:
如果索引存在,而Time Filter field name的选项也没问题,那么单击Create即可完成索引的添加。
如果在输入索引名称后提示“Unable to fetch mapping. Do you have indices matching the pattern?”,这是因为索引不存在导致的:
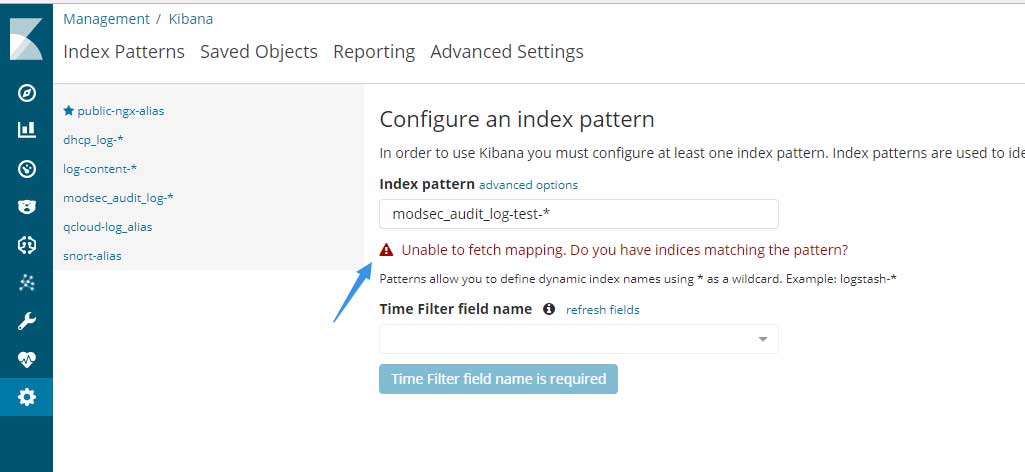
这时候请打开Dev Tools,然后在Console中输入以下内容并单击运行键:
GET _cat/indices?v
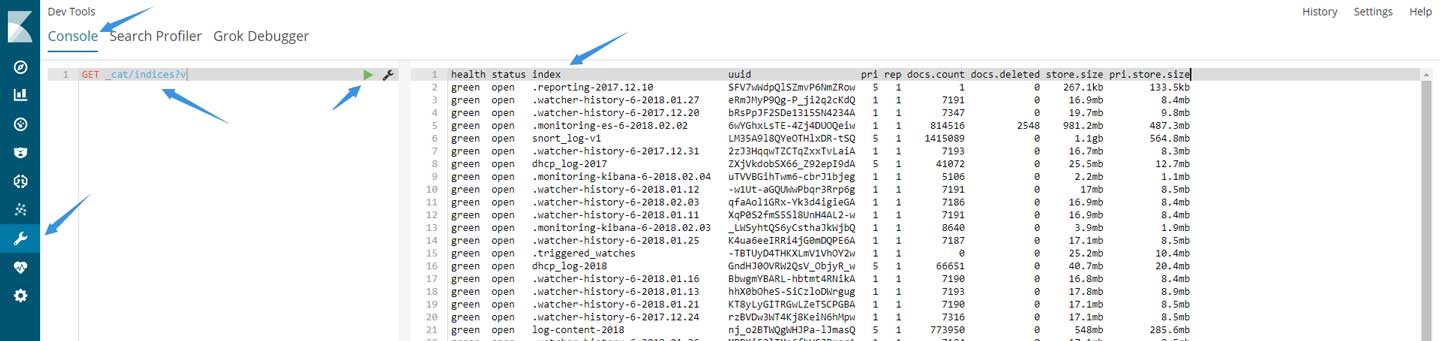
成功运行后在右侧窗口中会展现出elasticsearch中存在的所有索引及其信息,请再次确认相关索引的名称。
0x03 fields type
原始日志经过logstash处理后会以json的形式输出,我习惯将json的key成为字段,而value则称为字段的内容。
我们知道日志中包含IP地址、时间和字节等等的格式化内容,而这些值都存在不同名称的key(字段)内,成为该字段的内容,例如:
"client_ip": "45.32.20.000" "timestamp": "04/Feb/2018:22:21:51 +0800", "upstream_response_time": "1.590"
默认情况下,elasticsearch会将所有字段都标识为字符串( string),那么在生成图表的时候会有一些问题。如上面三个字段:
- client_ip:可以将IP地址表示为IP地址,而不是字符串,但我还没发现有什么具体的用途;
- timestamp:需要将时间表示为时间才可以被@timestemp采用;
- upstream_response_time:这种计数的时间和数值可以看做是同一类,因为要标识为number才能用于加减,很明显字符串是不能用于运算的。
所有支持的fields type请参考官方文档:
在日常使用中,我觉得数字类型的选择要谨慎,要注意整数与浮点数的区别和每种类型的取值范围:

fields type需要在建立索引之后,写入数据之前确立,一旦写入数据,就不可以再次修改该索引中的fields type。如果需要修改,就需要通过reindex这个API对数据进行倒腾,具体可以参考以下文章:
如果你的数据量特别巨大,这会需要很长的时间,而且可能会导致现有的服务中断。我建议在索引建立之初建立一个别名,这样可以减少服务中断的时间,甚至实现0中断。相关内容可以参考以下文章:
更重要的还是索引所对应的模板,模板内记录着字段类型的mapping(映射),相关内容可以参考以下文章:
- 详解安装配置Elastic Stack 6并分析nginx日志-0x07 初始化配置
- Elasticsearch Reference [6.1] » Indices APIs » Index Templates
如果logstash分词无误,同时索引模板也生效了,那么通过Management–>Index Patterns页面查看相关索引fields将会是这样的:
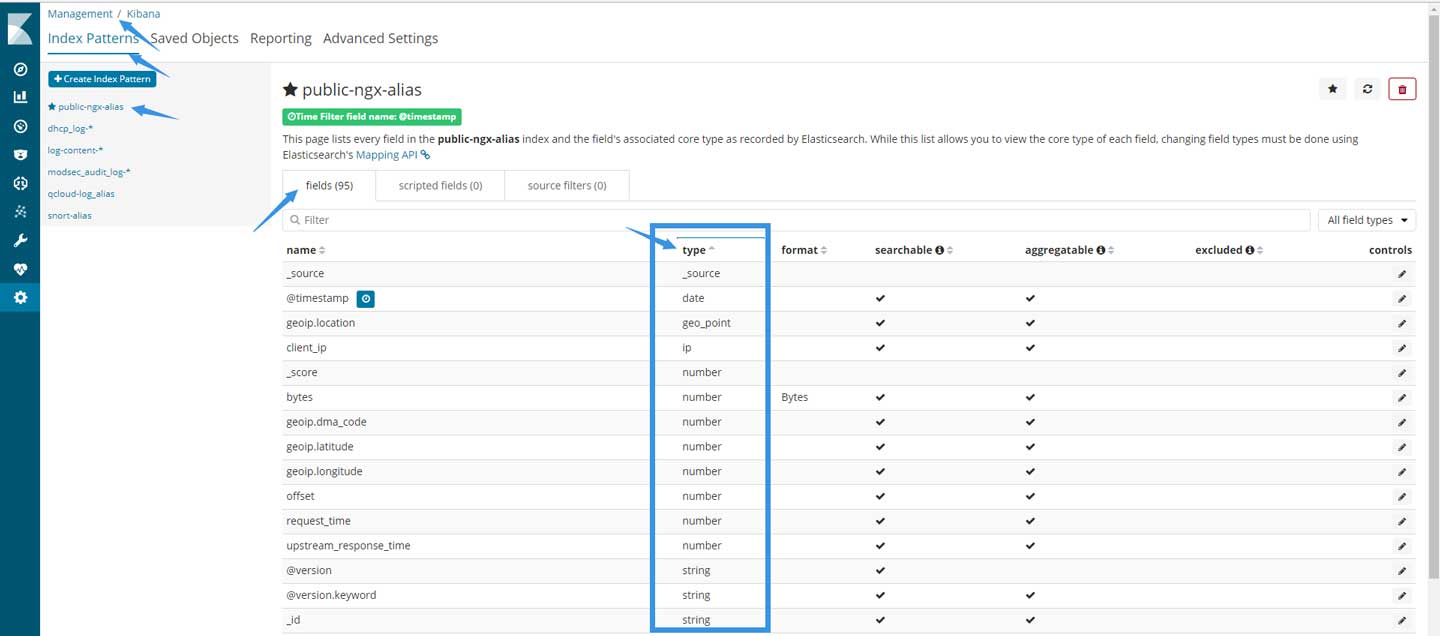
可以看到type一栏有些字段的类型不再是默认的string(字符串)了。
0x04 fields format
在开始这个部分的内容前先理解下面这句话:
同一种类型的数据有不同类型的表达方式
举个例子:
"bytes": "124779"
上面是某条日志中记录的传输字节,它是一串数字,所以它的fields type为:long。
这里有个问题:
- 既然是字节,为什么fields type不是:byte?
我们看看long和byte在官网中的描述:
long A signed 64-bit integer with a minimum value of -263 and a maximum value of 263-1. byte A signed 8-bit integer with a minimum value of -128 and a maximum value of 127.
再看看例子中的数值:124779,很明显,这个数字的大小已经超出了8字节的范围,所以我在模板中将它定义为:long。
而long几乎可表达一切我们需要的数值,所以我在一般环境中时常使用该类型标识数值。
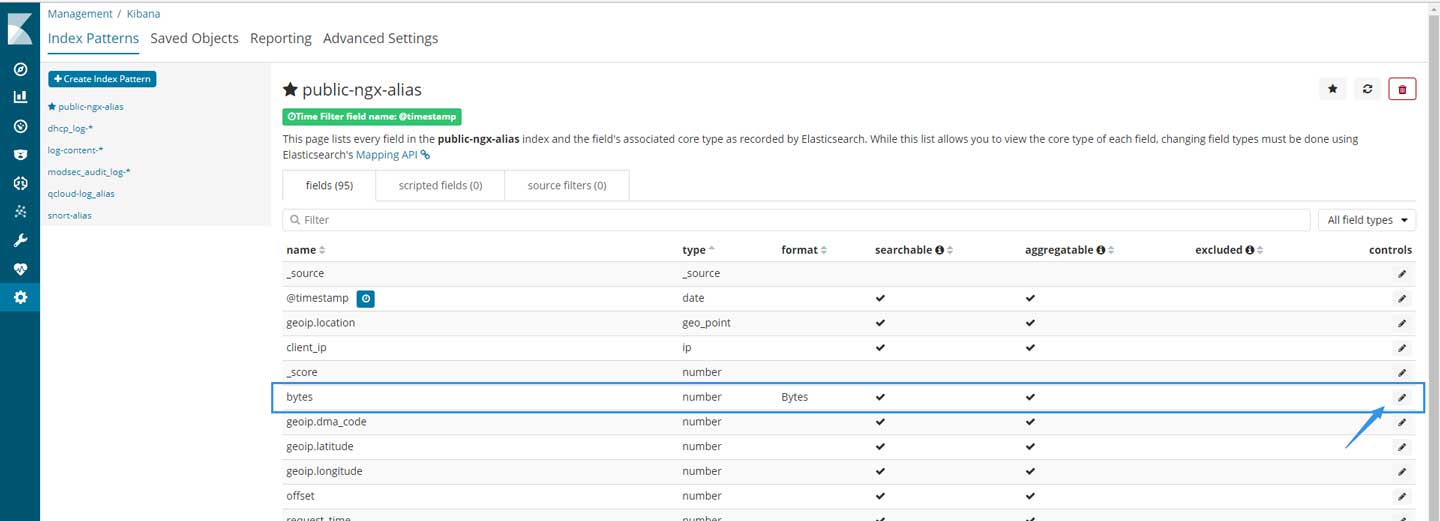
但将一串数字标识为:long并不能表示它就是byte,这时候fields format就可以上场了。首先回顾这种图,注意看format的部分:
其中名为byte的字段被标识为number,而且格式被指定为Byte。
其实只要在index模板中被标识为number相关的类型,都会被标识为number。所以在实际应用中可以选择一个合适范围大小的类型,如:long,然后再修改format即可。
format的修改也很简单,不过在修改前要注意:如果已经使用该字段生成了可视化图表,此时再修改字段格式就有可能使得可视化图表产生错误。
举个例子:
我用6个0表示黑色:000000,然后在可视化图表中将这个颜色展示出来;可是现在我将它的格式修改为Byte,那么这个统计就会出错。
而这个fields format的修改也很简单,先按照上面的描述进入索引的设置界面,然后找到需要设置的字段,点击修改按钮:
打开后,正常情况下应该是这样的:
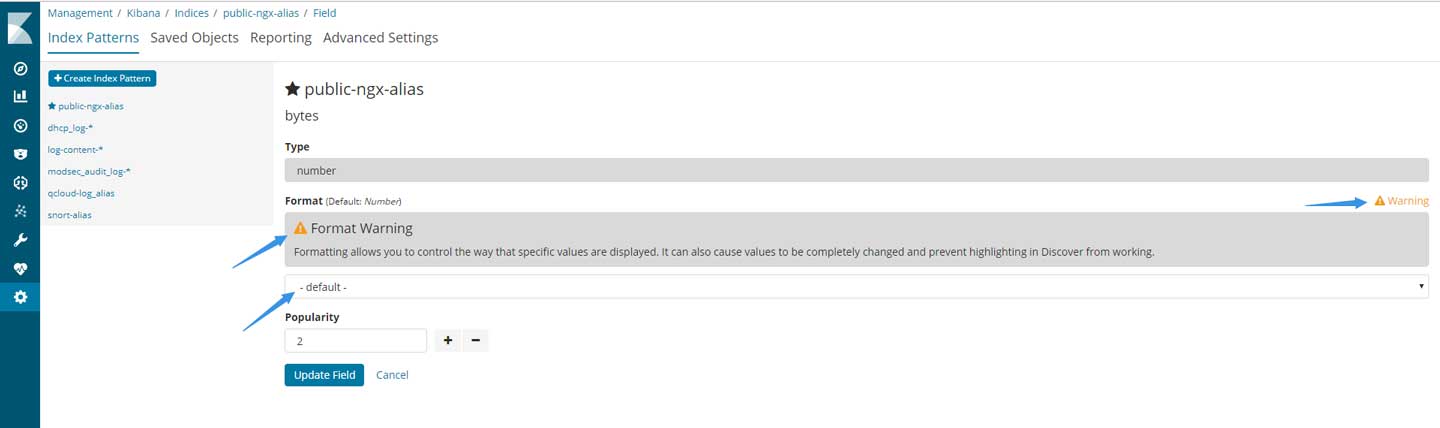
如果已经使用该字段创建了可视化图表,那么会有个警告,点击后是详细的告警内容;最底下是小数位的设置,默认为2位小数。而中间就是默认的fields format,默认是default。
请根据实际的需要选择fields format:
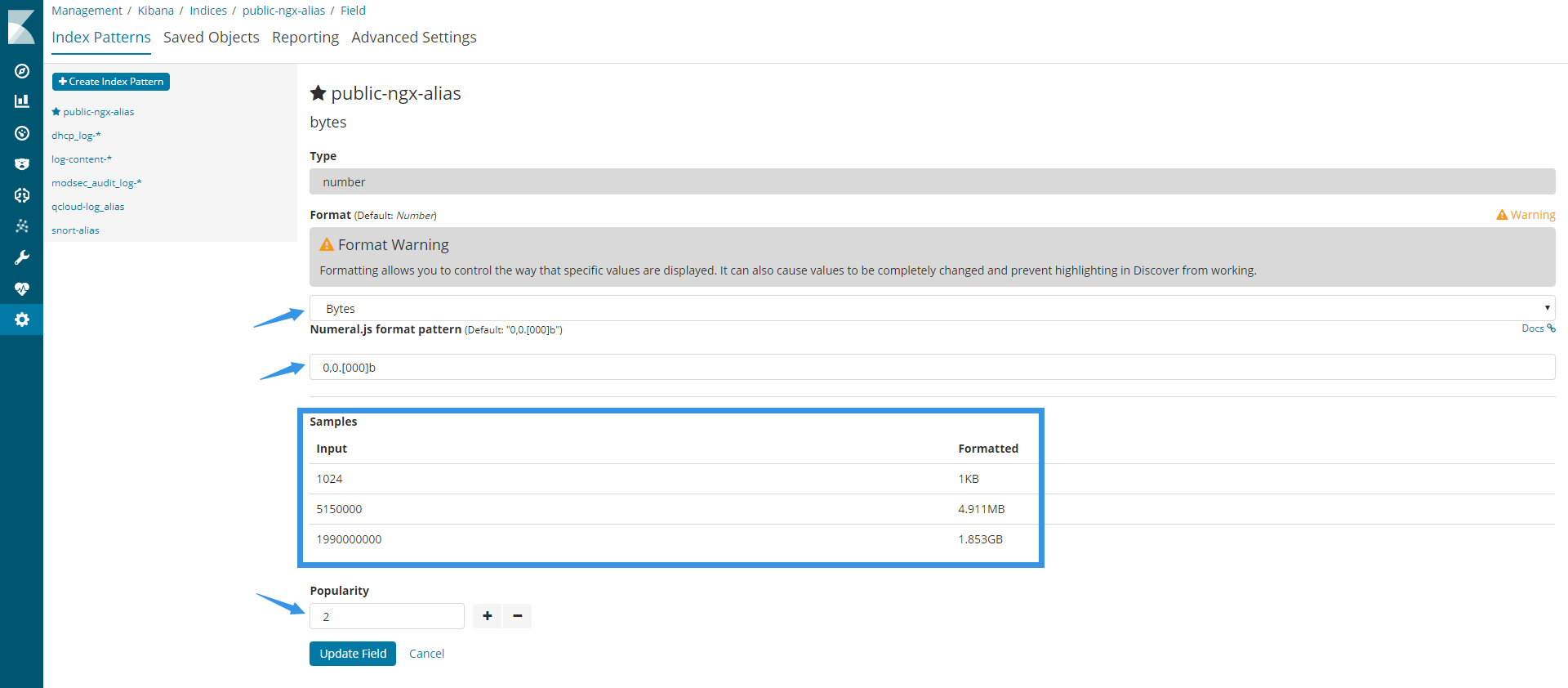
Numeral.js format pattern如果没有特殊要求,保持默认即可。如果数字的格式比较特别,可以手动进行修改。
有些fields format会自动换算并加上单位的,如图中Samples中的内容所示,会自动将Byte进行换算。
0x05 结语
需要注意和准备的内容就那么多,简单来说有以下几点:
- 确立索引的命名规则;
- 确立各个字段的类型,默认为字符串的字段可以忽略;
- 为该命名规则的索引建立通用的索引模板;
- 将索引模板导入至elasticsearch;
- 传入数据;
- 修正fields format
- 建立可视化图表
因为来回倒腾数据很痛苦,一定要提前确立所有东西,也不要轻易修改!















VPS服务商3年使用总结")






