
0x01 前言
在写这篇文章的前几个月,Elastic已经发布了6.0版本。这篇文章内的所有内容都是以最新版本为基础进行编写的。
我之前已经写过好多篇关于elasticstack这个技术栈的文章,而今天我将这些文章做一个整合处理,将所有知识点和要点重新梳理,形成一篇elasticstack技术栈的入门文章。
更为详细的使用手册可以参考官方网站的文档:
0x02 准备
安装的过程可以参考以下文章,以便与本篇文章进行互补:
我依旧采用centos7作为底层系统,使用我家中的的镜像作为源地址,如果本地没有可用的源镜像,那么推荐使用清华大学的镜像:
https://mirrors.tuna.tsinghua.edu.cn/elasticstack/yum/elastic-6.x/
在/etc/yum.repos.d目录下新建以下文件并写入内容即可:
[root@elk6-t1 ~]# cat /etc/yum.repos.d/elasticsearch-6.x.repo [elasticsearch-6.x] name=Elasticsearch repository for 6.x packages baseurl=https://mirrors.tuna.tsinghua.edu.cn/elasticstack/yum/elastic-6.x/ gpgcheck=0 enabled=1 autorefresh=1 type=rpm-md
然后先清理yum缓存再安装jdk与elasticstack套件:
[root@elk6-t1 ~]# yum install java-1.8.0-openjdk kibana logstash filebeat elasticsearch
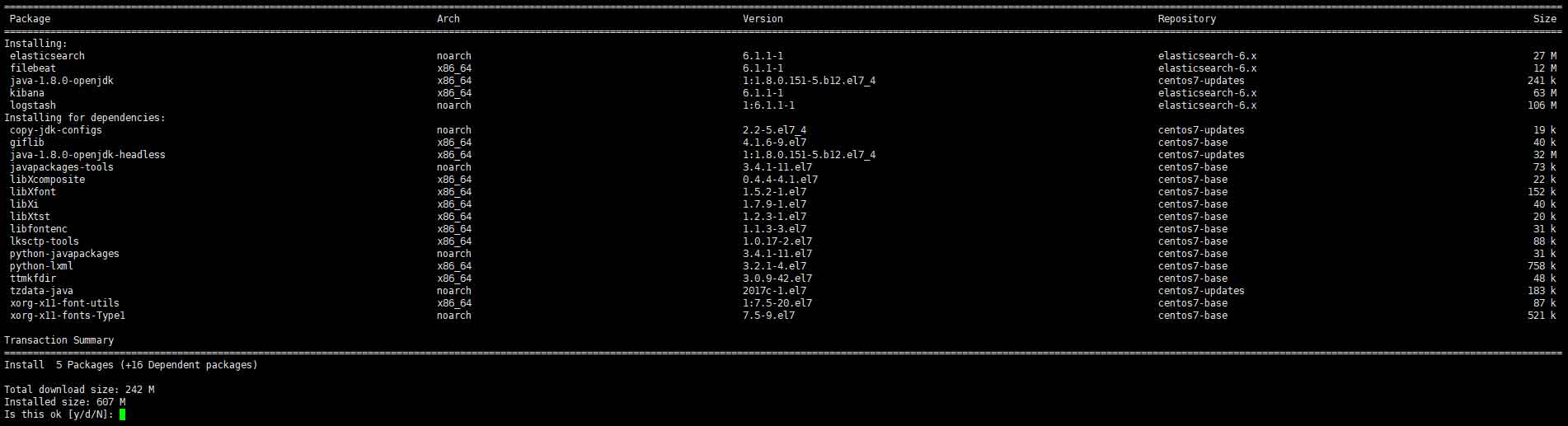
再继续之前先讲解elasticstack的基础知识,首先常用的套件包含以上4个独立的软件,而这些软件都依赖java环境,所以需要安装openjdk。
其中各个软件的功用如下:
- kibana:一个用户友好的GUI控制界面,可从elasticsearch中读取数据并生成各种酷炫的图表;
- Beats平台:Beast都是以agent的形式存在系统中并展开监视工作,读取后的数据可以发送至logstash进行处理或发送至elasticsearch进行存储。比较典型的有Packetbeat,、Filebeat、Metricbeat和Winlogbeat:
- Packetbeat:主要收集数据包的代理;
- Filebeat:主要收集文本日志的代理;
- Metricbeat:主要收集系统和软件的性能或其他指标数据的代理;
- Winlogbeat:主要收集windows系统日志的代理。
- logstash:一个开源的实时数据处理与收集引擎。
以上软件的工作流程如下图:
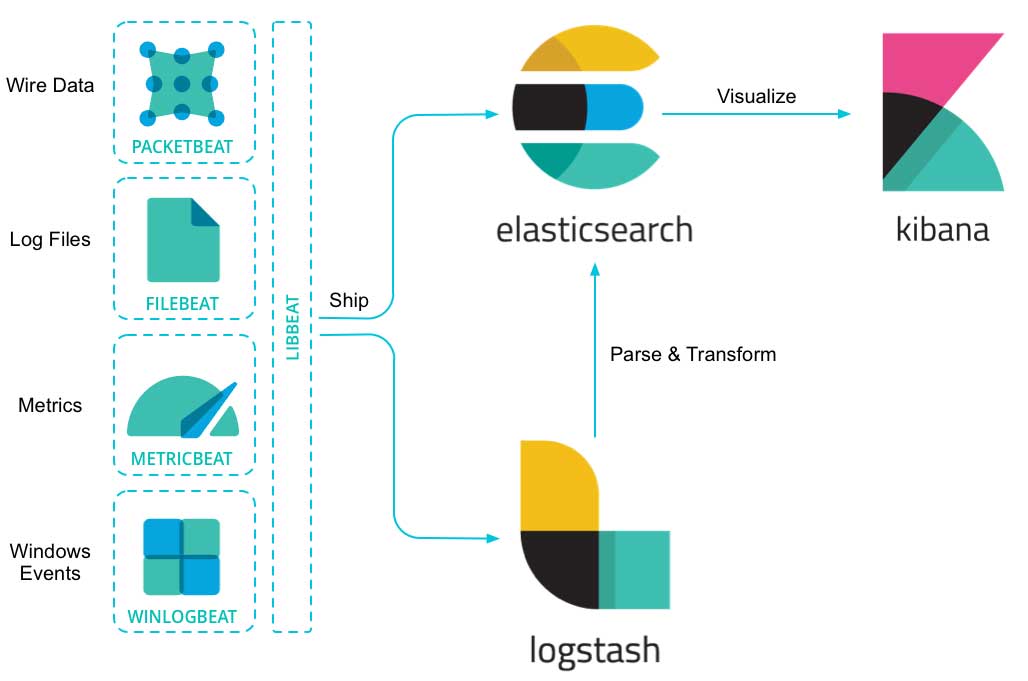
从上图可以看出Beast一侧主要工作为收集数据;收集到的数据可以发送至logstash进行分词处理再进行归档存储,也可以直接发送至elasticsearch归档存储;最终用户通过kibana从elasticsearch中搜索数据并进行可视化操作。
安装完成后需要先修改配置文件,官方推荐的配置顺序为elasticsearch–>kibana–>beast。但我更倾向于先配置kibana,然后再配置elasticsearch等。
0x03 kibana
先检查service启动文件:
[root@elk6-t1 ~]# cat /etc/systemd/system/kibana.service [Unit] Description=Kibana [Service] Type=simple User=kibana Group=kibana # Load env vars from /etc/default/ and /etc/sysconfig/ if they exist. # Prefixing the path with '-' makes it try to load, but if the file doesn't # exist, it continues onward. EnvironmentFile=-/etc/default/kibana EnvironmentFile=-/etc/sysconfig/kibana ExecStart=/usr/share/kibana/bin/kibana "-c /etc/kibana/kibana.yml" Restart=always WorkingDirectory=/ [Install] WantedBy=multi-user.target
可以看出可执行文件与配置文件的路径,下面先修改配置文件,请根据实际情况进行修改:
#默认监听TCP 5601端口,如果有需要,可以改为80或其他端口 server.port: 5601 #监听的IP,默认为localhost,我将它改为0.0.0.0,即监听所有IP server.host: "localhost" #kibana服务器名称,如果有多个kibana节点,建议修改这个参数以便识别 server.name: "your-hostname" #elasticsearch的地址,如果elasticsearch与kibana安装在不同服务器上,需要手动指定地址 elasticsearch.url: "http://localhost:9200" #kibana会在elasticsearch中创建一个索引用于存储kibana的设置,索引名称可以自定义。一般无需修改 kibana.index: ".kibana" #elasticsearch请求超时阈值,如果数据量及其庞大,可适当增加该值 elasticsearch.requestTimeout: 30000
其他参数诸如elasticsearch用户名与密码,这个需要安装x-pack后才需要配置,SSL的配置将在以后文章中详细说明。完成配置后即可启动kibana:
#立即启动kibana
[root@elk6-t1 ~]# systemctl start kibana.service
#将kibana设为开机启动
[root@elk6-t1 ~]# systemctl enable kibana.service
Created symlink from /etc/systemd/system/multi-user.target.wants/kibana.service to /etc/systemd/system/kibana.service.
#检查kibana的状态
[root@elk6-t1 ~]# systemctl status kibana.service
● kibana.service - Kibana
Loaded: loaded (/etc/systemd/system/kibana.service; enabled; vendor preset: disabled)
Active: active (running) since Sun 2018-01-21 19:43:39 CST; 7s ago
Main PID: 4247 (node)
CGroup: /system.slice/kibana.service
└─4247 /usr/share/kibana/bin/../node/bin/node --no-warnings /usr/share/kibana/bin/../src/cli -c /etc/kibana/kibana.yml
如果一切正常,那么你将看到以下界面:

因为还没有配置elasticsearch,所以服务状态为Red,同时plugin:[email protected]存在告警:
Unable to connect to Elasticsearch at http://localhost:9200.
这是因为kibana无法连接到elasticsearch,无法读取.kibana这个索引的内容。
0x04 elasticsearch
接下来配置elasticsearch,和kibana一样,elasticsearch的bin目录与配置文件路径分别如下:
#elasticsearch配置文件路径 [root@elk6-t1 ~]# ll -alh /etc/elasticsearch/ total 28K drwxr-s--- 2 root elasticsearch 72 Jan 21 14:41 . drwxr-xr-x. 90 root root 8.0K Jan 21 14:42 .. -rw-rw---- 1 root elasticsearch 2.9K Dec 18 04:24 elasticsearch.yml -rw-rw---- 1 root elasticsearch 2.7K Dec 18 04:24 jvm.options -rw-rw---- 1 root elasticsearch 5.0K Dec 18 04:24 log4j2.properties #elasticsearch可执行文件路径 [root@elk6-t1 ~]# ll -alh /usr/share/elasticsearch/ total 224K drwxr-xr-x 6 root root 110 Jan 21 14:41 . drwxr-xr-x. 111 root root 4.0K Jan 21 14:42 .. drwxr-xr-x 2 root root 135 Jan 21 14:41 bin drwxr-xr-x 2 root root 4.0K Jan 21 14:41 lib -rw-r--r-- 1 root root 12K Dec 18 04:22 LICENSE.txt drwxr-xr-x 15 root root 4.0K Jan 21 14:41 modules -rw-r--r-- 1 root root 188K Dec 18 04:24 NOTICE.txt drwxr-xr-x 2 root root 6 Dec 18 04:24 plugins -rw-r--r-- 1 root root 9.2K Dec 18 04:22 README.textile
elasticsearch配置文件中的内容不多,但绝大部分都需要手动配置:
#配置集群名称,无论是否计划建立集群,建议配置一个名称 cluster.name: my-application #该elasticsearch节点的名称,如果需要建立集群,该节点名称不可重复!!! node.name: node-1 #elasticsearch数据存储和日志的路径 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch #监听的IP与端口,默认为127.0.0.1:9200,如果需要监听其他IP,请手动配置。但端口一般保持默认。 network.host: 0.0.0.0 http.port: 9200 #默认情况下,elasticsearch会自动搜索同一网络中所有可用的节点,当然,节点配置的集群名称必须相同。 #如果节点存在于不同的网络或网络不可达,那么就需要手动配置以下参数,单机运行则不需要配置。 discovery.zen.ping.unicast.hosts: ["host1", "host2"] #如果启用了集群模式,那么以下参数至关重要。 #主要是为了方式脑裂现象的发生,且必须有一半以上的节点处于可用状态,否则将导致服务崩溃。 #该数值建议的计算公式为:(master_eligible_nodes / 2) + 1 discovery.zen.minimum_master_nodes: 3 #设定当多少个节点介入该集群后即开始数据恢复工作 gateway.recover_after_nodes: 2 #另外为了方便使用,可以在配置文件最底部加入以下内容, #允许通过任何途径在elasticsearch中创建索引。 #注意!请勿在生产环境中使用,会有安全问题! action.auto_create_index: +*
数据存储的路径可以有多个值,理想情况下可以均衡负载。但我在实际使用中发现配置生效的时间必须早于索引建立的时间才有效。
多个数据存储路径的配置格式如下:
path:
data:
- /mnt/elasticsearch_1
- /mnt/elasticsearch_2
- /mnt/elasticsearch_3
完成配置后即可通过以下命令启动elasticsearch:
#立即启动elasticsearch
[root@elk6-t1 ~]# systemctl restart elasticsearch.service
#将elasticsearch设为开机启动
[root@elk6-t1 ~]# systemctl enable elasticsearch.service
Created symlink from /etc/systemd/system/multi-user.target.wants/elasticsearch.service to /usr/lib/systemd/system/elasticsearch.service.
#检查状态
[root@elk6-t1 ~]# systemctl status elasticsearch.service
● elasticsearch.service - Elasticsearch
Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; disabled; vendor preset: disabled)
Active: active (running) since Sun 2018-01-21 20:20:24 CST; 3s ago
Docs: http://www.elastic.co
Main PID: 4403 (java)
CGroup: /system.slice/elasticsearch.service
└─4403 /bin/java -Xms1g -Xmx1g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+AlwaysPreTouch -server -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -XX:-OmitStackTraceInFastThro...
Jan 21 20:20:24 elk6-t1 systemd[1]: Started Elasticsearch.
Jan 21 20:20:24 elk6-t1 systemd[1]: Starting Elasticsearch...
如果一切正常,那么刷新kibana后即可看到以下界面:
如果还是提示无法连接elasticsearch,请重新检查kibana的配置文件与elasticsearch服务是否已经启动,必要时可以重启kibana服务。
0x05 logstash
logstash功能非常强大,不仅仅是分析传入的文本,还可以作监控与告警之用。在这里主要讲解分析的配置与使用经验。
logstash的bin目录与配置文件路径都与kibana和elasticsearch类似:
#logstash配置文件路径 [root@elk6-t1 ~]# ll -alh /etc/logstash/ total 32K drwxr-xr-x 3 root root 102 Jan 21 14:41 . drwxr-xr-x. 90 root root 8.0K Jan 21 14:42 .. drwxrwxr-x 2 root root 6 Dec 18 05:51 conf.d -rw-r--r-- 1 root root 1.7K Dec 18 05:51 jvm.options -rw-r--r-- 1 root root 1.4K Dec 18 05:51 log4j2.properties -rw-r--r-- 1 root root 6.3K Jan 21 14:41 logstash.yml -rw-r--r-- 1 root root 1.7K Dec 18 05:51 startup.options #logstash可执行文件路径 [root@elk6-t1 ~]# ll -alh /usr/share/logstash/ total 76K drwxr-xr-x 10 logstash logstash 4.0K Jan 21 14:41 . drwxr-xr-x. 111 root root 4.0K Jan 21 14:42 .. drwxr-xr-x 2 logstash logstash 4.0K Jan 21 14:41 bin -rw-r--r-- 1 logstash logstash 2.3K Dec 18 05:51 CONTRIBUTORS drwxrwxr-x 2 logstash logstash 6 Dec 18 05:51 data -rw-r--r-- 1 logstash logstash 3.8K Dec 18 05:51 Gemfile -rw-r--r-- 1 logstash logstash 21K Dec 18 05:51 Gemfile.lock drwxr-xr-x 5 logstash logstash 62 Jan 21 14:41 lib -rw-r--r-- 1 logstash logstash 589 Dec 18 05:51 LICENSE drwxr-xr-x 4 logstash logstash 108 Jan 21 14:41 logstash-core drwxr-xr-x 3 logstash logstash 55 Jan 21 14:41 logstash-core-plugin-api drwxr-xr-x 4 logstash logstash 52 Jan 21 14:41 modules -rw-rw-r-- 1 logstash logstash 27K Dec 18 05:51 NOTICE.TXT drwxr-xr-x 3 logstash logstash 29 Jan 21 14:41 tools drwxr-xr-x 4 logstash logstash 31 Jan 21 14:41 vendor
logstash的配置文件完全不需要修改:
#logstash数据存储路径,保持默认即可 path.data: /var/lib/logstash #logstash动态加载的配置文件,所有自定义的输入、输出和过滤配置都放置在这个目录中并以.conf结尾 path.config: /etc/logstash/conf.d/*.conf #logstash日志文件路径,保持默认即可 path.logs: /var/log/logstash
0x05.1 输入配置
在启动之前需要先编写输入、输出和过滤的配置文件,以下是我常用的一些配置文件,不同类型的配置文件可加上数字前缀,以便区分:
[root@logstash6-node1 ~]# ll /etc/logstash/conf.d/ total 36 -rw-r--r-- 1 root root 121 Dec 11 16:32 00-8014.conf -rw-r--r-- 1 root root 290 Dec 11 16:32 01-8015.conf -rw-r--r-- 1 root root 41 Dec 11 16:32 02-8016.conf -rw-r--r-- 1 root root 169 Dec 11 16:32 03-8017.conf -rw-r--r-- 1 root root 3336 Dec 11 16:33 10-nginx-fliter.conf -rw-r--r-- 1 root root 591 Dec 11 16:35 11-cdn-fliter.conf -rw-r--r-- 1 root root 774 Dec 11 16:35 12-dhcp-fliter.conf -rw-r--r-- 1 root root 462 Dec 11 16:35 13-snort-fliter.conf -rw-r--r-- 1 root root 1524 Dec 17 23:12 99-output.conf
如果需要与best通过公网进行通讯,建议使用SSL加密,那么输入的配置文件如下:
[root@logstash6-node1 ~]# cat /etc/logstash/conf.d/01-8015.conf
input {
beats {
port => 8015
ssl => true
ssl_certificate_authorities => ["/etc/logstash/elk_server_crt/ca.crt"]
ssl_certificate => "/etc/logstash/elk_server_crt/server.crt"
ssl_key => "/etc/logstash/elk_server_crt/server.key"
ssl_verify_mode => "force_peer"
}
}
相关的数字证书可自行签发,签发过程可参考以下文章:
如果需要监听514端口,则logstash需要以root用户启动,请手动修改以下文件:
#修改以下文件 [root@logstash6-node1 ~]# vim /etc/systemd/system/logstash.service #将user与group修改为root即可 [Unit] Description=logstash [Service] Type=simple User=logstash Group=logstash # Load env vars from /etc/default/ and /etc/sysconfig/ if they exist. # Prefixing the path with '-' makes it try to load, but if the file doesn't # exist, it continues onward. EnvironmentFile=-/etc/default/logstash EnvironmentFile=-/etc/sysconfig/logstash ExecStart=/usr/share/logstash/bin/logstash "--path.settings" "/etc/logstash" Restart=always WorkingDirectory=/ Nice=19 LimitNOFILE=16384 [Install] WantedBy=multi-user.target
如果需要监听其他TCP或UDP端口,可以参考以下配置:
#监听TCP与UDP的8014端口
[root@logstash6-node1 ~]# cat /etc/logstash/conf.d/00-8014.conf
input {
tcp {
type => "syslog"
port => 8014
}
}
input {
udp {
type => "syslog"
port => 8014
}
}
logstash还支持多种输入方式,具体请参考官方的说明:
0x05.2 输出配置
logstash可以在上层配置一个负载均衡器实现集群,在实际应用中,logstash服务需要处理多种不同类型的日志或数据,处理后的日志或数据需要存放在不同的elasticsearch集群或索引中,那么就需要对日志进行分门别类。
更多相关的信息可以参考官方的文档:
而我的logstash服务节点只有一个,需要处理多达6种不同类型的日志,所以我的输出配置如下:
[root@logstash6-node1 ~]# cat /etc/logstash/conf.d/99-output.conf
output {
if "server_ngx_access_log" in [tags] {
elasticsearch {
hosts => ["es6-node1.t.com:9200", "es6-node2.t.com:9200", "es6-node3.t.com:9200"]
manage_template => false
index => "public-ngx-alias"
}
} else if "tencent_cdn" in [tags] {
elasticsearch {
hosts => ["es6-node1.t.com:9200", "es6-node2.t.com:9200", "es6-node3.t.com:9200"]
manage_template => false
index => "tencent-cdn-%{+YYYY}"
}
} else if "dhcp_log" in [tags] {
elasticsearch {
hosts => ["es6-node1.t.com:9200", "es6-node2.t.com:9200", "es6-node3.t.com:9200"]
manage_template => false
index => "dhcp_log-%{+YYYY}"
}
} else if "snort_log" in [tags] {
elasticsearch {
hosts => ["es6-node1.t.com:9200", "es6-node2.t.com:9200", "es6-node3.t.com:9200"]
manage_template => false
index => "snort-alias"
}
} else if "modsec_audit_log" in [tags] {
elasticsearch {
hosts => ["es6-node1.t.com:9200", "es6-node2.t.com:9200", "es6-node3.t.com:9200"]
manage_template => false
index => "modsec_audit_log-%{+YYYY}"
}
} else if "win32_log" in [tags] {
elasticsearch {
hosts => ["es6-node1.t.com:9200", "es6-node2.t.com:9200", "es6-node3.t.com:9200"]
manage_template => false
index => "win32_log-%{+YYYY}"
}
} else {
elasticsearch {
hosts => ["es6-node1.t.com:9200", "es6-node2.t.com:9200", "es6-node3.t.com:9200"]
manage_template => false
index => "log-content-%{+YYYY}"
}
}
}
通过在output配置中设定判断语句,将处理后的数据存放到不同的索引中。而这个tags的添加有以下三种途径:
- 在filebeat读取数据后,向logstash发送前添加到数据中;
- logstash处理日志的时候,向tags标签添加自定义内容;
- 在logstash接收传入数据时,向tags标签添加自定义内容。
在这里先说明第3中情况:
[root@logstash6-node1 ~]# cat /etc/logstash/conf.d/03-8017.conf
input {
tcp {
type => "syslog"
port => 8017
tags => "win32_log"
}
}
input {
udp {
type => "syslog"
port => 8017
tags => "win32_log"
}
}
从上面的输入配置文件中可以看出,在logstash接收到从TCP或UDP 8017端口传入的数据时,随机在tags标签加上自定义的win32_log标签。
这个操作除非在后续处理处理数据的时候手动将其删除,否则将永久存在该数据中。
elasticsearch字段中的各参数的意义如下:
- hosts:指定elasticsearch地址,如有多个节点可用,可以设为array模式,可实现负载均衡;
- manage_template:如果该索引没有合适的模板可用,默认情况下将由默认的模板进行管理;
- index:指定存储数据的索引
0x05.3 筛选处理
输入和输出在logstash配置中是很简单的一步,而对数据进行匹配处理则显得异常复杂。匹配当行日志是入门水平需要掌握的,而多行甚至不规则的日志则可能需要ruby的协助。
更多的信息请关注官方的文档:
在这里我主要展示使用grok这个插件,你可以浏览以下文章,和此文章进行互补:
以下是我nginx的access日志格式:
49.115.208.10 - - [21/Jan/2018:21:16:02 +0800] "GET /wp-content/uploads/2017/11/1509543249.jpg HTTP/2.0" ngx.hk 200 39288 "https://ngx.hk/2017/11/02/%E5%AE%89%E8%A3%85%E9%85%8D%E7%BD%AEvmware-vcenter-6-5-vcsa-6-5.html" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36" "-" - - HIT "image/jpeg" - > 0.000
以下是该日志的grok捕获语法:
%{IPORHOST:client_ip} - %{USER:auth} \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version})?|-)\" (%{IPORHOST:domain}|%{URIHOST:domain}|-) %{NUMBER:response} %{NUMBER:bytes} %{QS:referrer} %{QS:agent} \"(%{WORD:x_forword}|-)\" (%{URIHOST:upstream_host}|-) (%{NUMBER:upstream_response}|-) (%{WORD:upstream_cache_status}|-) %{QS:upstream_content_type} (%{BASE16FLOAT:upstream_response_time}|-) > %{BASE16FLOAT:request_time}
相关的语法可以参考以下GitHub页面:
在编写grok捕获规则时,可以使用以下网站进行辅助:
如果语法没问题,那么会显示以下界面:

我nginx日志完整的筛选处理配置文件如下:
[root@logstash6-node1 ~]# cat /etc/logstash/conf.d/10-nginx-fliter.conf
filter {
if "server_ngx_access_log" in [tags] {
grok {
match => { "message" => "%{IPORHOST:client_ip} - %{USER:auth} \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version})?|-)\" (%{IPORHOST:domain}|%{URIHOST:domain}|-) %{NUMBER:response} %{NUMBER:bytes} %{QS:referrer} %{QS:agent} \"(%{WORD:x_forword}|-)\" (%{URIHOST:upstream_host}|-) (%{NUMBER:upstream_response}|-) (%{WORD:upstream_cache_status}|-) %{QS:upstream_content_type} (%{BASE16FLOAT:upstream_response_time}|-) > %{BASE16FLOAT:request_time}" }
match => { "message" => "%{IPORHOST:upstream_host} - %{USER:auth} \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version})?|-)\" (%{IPORHOST:domain}|%{URIHOST:domain}|-) %{NUMBER:response} %{NUMBER:bytes} %{QS:referrer} %{QS:agent} \"%{IP:client_ip}\" (%{URIHOST:upstream_host}|-) (%{NUMBER:upstream_response}|-) (%{WORD:upstream_cache_status}|-) %{QS:upstream_content_type} (%{BASE16FLOAT:upstream_response_time}|-) > %{BASE16FLOAT:request_time}" }
match => { "message" => "%{IPORHOST:client_ip} - (%{USER:auth}|-) \[%{HTTPDATE:timestamp}\] \"%{WORD:verb} %{NOTSPACE:request} HTTP/%{NUMBER:http_version}\" (%{IPORHOST:domain}|%{URIHOST:domain}|-) %{NUMBER:response} %{NUMBER:bytes} %{QS:referrer} %{QS:agent} \"(%{WORD:x_forword}|%{IPORHOST:x_forword}|-)\" (%{IPORHOST:upstream_host}|-)\:%{NUMBER:upstream_port} (%{NUMBER:upstream_response}|-) (%{WORD:upstream_cache_status}|-) \"%{NOTSPACE:upstream_content_type}; charset\=%{NOTSPACE:upstream_content_charset}\" (%{BASE16FLOAT:upstream_response_time}|-) > %{BASE16FLOAT:request_time}" }
match => { "message" => "%{IPORHOST:client_ip} - (%{USER:auth}|-) \[%{HTTPDATE:timestamp}\] \"%{WORD:verb} %{NOTSPACE:request} HTTP/%{NUMBER:http_version}\" (%{IPORHOST:domain}|%{URIHOST:domain}|-) %{NUMBER:response} %{NUMBER:bytes} %{QS:referrer} %{QS:agent} \"(%{WORD:x_forword}|%{IPORHOST:x_forword}|-)\" (%{IPORHOST:upstream_host}|-)\:%{NUMBER:upstream_port} (%{NUMBER:upstream_response}|-) (%{WORD:upstream_cache_status}|-) \"%{NOTSPACE:upstream_content_type};charset\=%{NOTSPACE:upstream_content_charset}\" (%{BASE16FLOAT:upstream_response_time}|-) > %{BASE16FLOAT:request_time}" }
match => { "message" => "%{IPORHOST:client_ip} - %{USER:auth} \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version})?|-)\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:agent}" }
match => { "message" => "%{IPORHOST:client_ip} - %{USER:auth} \[%{HTTPDATE:timestamp}\] \"(%{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version})?|-)\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:agent}" }
match => { "message" => "%{IPORHOST:client_ip} - %{USER:auth} \[%{HTTPDATE:timestamp}\] \"((%{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version})?|-)|)\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:agent}" }
match => { "message" => "%{IPORHOST:client_ip} - %{USER:auth} \[%{HTTPDATE:timestamp}\] %{QS:request} %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:agent}" }
}
geoip {
source => "client_ip"
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
useragent {
source => "agent"
target => "ua"
}
}
}
在filter段内的第一行是判断语句,如果server_ngx_access_log这个自定义字符在tags内则使用grok段内的语句对日志进行处理。
- geoip:使用GeoIP数据库对client_ip字段的IP地址进行解析,可得出该IP的经纬度、国家与城市等信息,但精确度不高,这主要依赖于GeoIP数据库;
- date:默认情况下,elasticsearch内记录的date字段是elasticsearch接收到该日志的时间,但在实际应用中需要修改为日志中所记录的时间。这时候则需要指定记录时间的字段并指定时间格式。如果匹配成功,则会将日志的时间替换至date字段中。
- useragent:这个主要为web app提供的解析,可以解析目前常见的一些useragent。
在防火墙、IDS或IPS应用环境中经常或遇到两组公网IP的情况,这时候的GeoIP配置可以类似以下这样进行设定:
[root@logstash6-node1 ~]# cat /etc/logstash/conf.d/13-snort-fliter.conf
filter {
grok {
match => { "message" => "\[%{INT:gid}:%{INT:sid}:%{INT:rev}\] %{DATA:alert} \[Classification: %{DATA:classification}\] \[Priority: %{INT:priority}\]: \<%{DATA:interface}\> {%{DATA:protocol}} %{IPV4:SrcIp}:%{INT:SrcPort}\ -> %{IPV4:DstIp}:%{INT:DstPort}" }
add_tag => ["snort_log"]
}
geoip {
source => "SrcIp"
target => "SrcGeo"
}
geoip {
source => "DstIp"
target => "DstGeo"
}
}
通过以上配置解析出来的日志格式如下:
"SrcGeo": {
"city_name": "Shenzhen",
"timezone": "Asia/Shanghai",
"ip": "113.116.159.193",
"latitude": 22.5333,
"country_name": "China",
"country_code2": "CN",
"continent_code": "AS",
"country_code3": "CN",
"region_name": "Guangdong",
"location": {
"lon": 114.1333,
"lat": 22.5333
},
"region_code": "44",
"longitude": 114.1333
},
"DstGeo": {
"city_name": "Huzhou",
"timezone": "Asia/Shanghai",
"ip": "61.174.50.190",
"latitude": 30.8703,
"country_name": "China",
"country_code2": "CN",
"continent_code": "AS",
"country_code3": "CN",
"region_name": "Zhejiang",
"location": {
"lon": 120.0933,
"lat": 30.8703
},
"region_code": "33",
"longitude": 120.0933
}
}
最后请注意配置文件grok字段中add_tag的配置,这个配置正是“0x05.2 输出配置”中所说的第2点情况:logstash处理日志的时候,向tags标签添加自定义内容。
完成后即可启动logstash服务,需要注意的是logstash启动时间较长,请耐心等待:
#立即启动logstash
[root@elk6-t1 ~]# systemctl start logstash.service
#将logstash设为开机启动
[root@elk6-t1 ~]# systemctl enable logstash.service
Created symlink from /etc/systemd/system/multi-user.target.wants/logstash.service to /etc/systemd/system/logstash.service.
#检查logstash服务状态
[root@elk6-t1 ~]# systemctl status logstash.service
● logstash.service - logstash
Loaded: loaded (/etc/systemd/system/logstash.service; enabled; vendor preset: disabled)
Active: active (running) since Sun 2018-01-21 21:59:16 CST; 40s ago
Main PID: 4712 (java)
CGroup: /system.slice/logstash.service
└─4712 /bin/java -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+DisableExplicitGC -Djava.awt.headless=true -Dfile.encoding=UTF-8 -XX:+HeapDumpOnOutOfMemoryError -Xmx1g -Xms256m -Xss204...
Jan 21 21:59:16 elk6-t1 systemd[1]: Started logstash.
Jan 21 21:59:16 elk6-t1 systemd[1]: Starting logstash...
Jan 21 21:59:53 elk6-t1 logstash[4712]: Sending Logstash's logs to /var/log/logstash which is now configured via log4j2.properties
在每次修改配置文件之后都需要重新启动logstash服务,为了减少downtime,建议先通过以下命令检查配置文件是否有效:
[root@logstash6-node1 ~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/10-nginx-fliter.conf -t WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console Configuration OK
0x06 filebeat
filebeat的相关文件路径与之前相差无几,先修改配置文件:
#打开文件进行修改
[root@elk6-t1 ~]# vim /etc/filebeat/filebeat.yml
filebeat.prospectors:
- input_type: log
paths:
- /usr/local/html/*/logs/ngx_access.log
- /var/log/nginx/access.log
tags: server_ngx_access_log
clean_*: true
- input_type: log
paths:
- /var/log/modsecurity/*/*/*
tags: modsec_audit_log
close_eof: true
clean_*: true
multiline.pattern: '---FfcUaIrf---Z--'
multiline.negate: true
multiline.match: after
output.logstash:
hosts: ["10.1.1.99:9200"]
ssl.certificate_authorities: ["/etc/filebeat/ela_ssl/ca.crt"]
ssl.certificate: "/etc/filebeat/ela_ssl/client.crt"
ssl.key: "/etc/filebeat/ela_ssl/client.key"
每个filebeat可以根据需求的不同拥有一个或多个prospectors,其他配置信息含义如下:
- input_type:输入内容,主要为逐行读取的log格式与标准输入stdin
- paths:指定需要读取日志的路径,如果路径拥有相同的结构,则可以使用通配符
- tags:为该路径的日志添加自定义tags,这与“0x05.2 输出配置”中所说的“在filebeat读取数据后,向logstash发送前添加到数据中”意义一致
- clean_:filebeat在这个路径有一个注册表文件:/var/lib/filebeat/registry,这个文件记录着filebeat读取过那些文件,还有已经读取的行数等信息。如果你的日志文件是定时分割,而且数量会随之增加,那么该注册表文件也会慢慢增大。随着注册表文件的增大,会导致filebeat检索的性能下降。更多该参数的含义,请先浏览官方说明:
- close_eof:正常情况下,filebeat会认为一个文件会不断地写入。如果你的文件只写入一边,那么建议启用该配置,告诉filebeat读取完成后关闭该文件,而后无论改文件是否更改,都不读取。请注意!该参数有风险,请注意你的日志文件是否使用close_eof这个参数。具体可参考官方说明:
- multiline.pattern:该参数适用于多行日志,如modsecurity日志,这部分内容在日后详解
- multiline.negate:该参数适用于多行日志,如modsecurity日志,这部分内容在日后详解
- multiline.match:该参数适用于多行日志,如modsecurity日志,这部分内容在日后详解
- output.logstash:定义内容输出的路径,这里主要输出到elasticsearch,其他的输出方式请参考官方说明:
- Filebeat Reference [6.1] » Configuring Filebeat » Configure the output
- hosts:指定服务器地址
- ssl:SSL加密的相关配置,请参考以下文章:
设定完成后先不要启动filebeat服务!
0x07 初始化配置
一旦启动filebeat,filebeat就会开始读取日志并发送至logstash进行处理,处理完成后的日志会发送至elasticsearch进行存储。
但在这里会有个问题,因为elasticsearch还没有配置索引与模板,如果直接接收logstash传入的日志,会导致后续的分析无法进行。
所以要先进行索引与模板的初始化配置,请注意!一旦索引与模板配置完成并接收数据后将无法修改字段类型与索引分片数量!
为了方便检查索引的状态与信息,建议先按照以下文章安装elasticsearch-head:
为了实现高可用,强烈建议使用别名配置索引,相关配置过程请参考以下文章:
例如“0x05.2 输出配置”中nginx日志需要输出至以下索引:
index => "public-ngx-alias"
这个“public-ngx-alias”为虚拟的索引,无需创建;需要创建一个名为“public-ngx_v1”的实体索引。
请注意虚拟索引与实体索引须有结构上的区别,例如上述例子中的“-”与“_”两个符号,这是为了方便模板匹配索引。
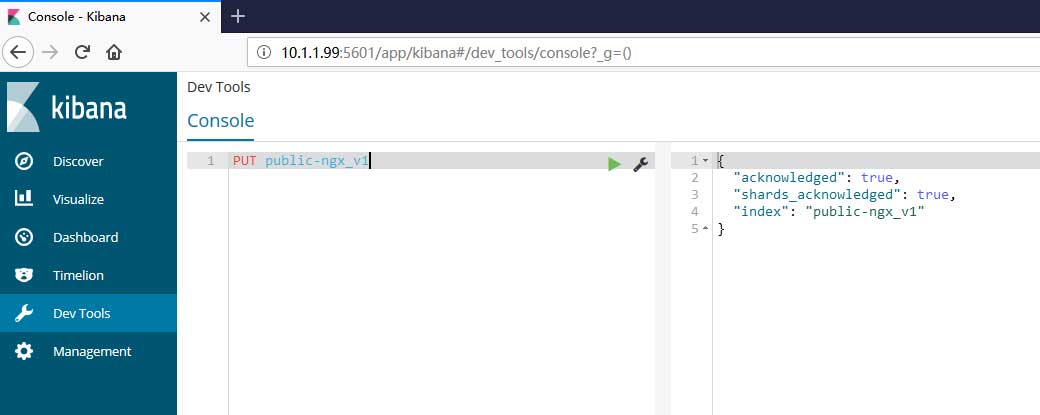
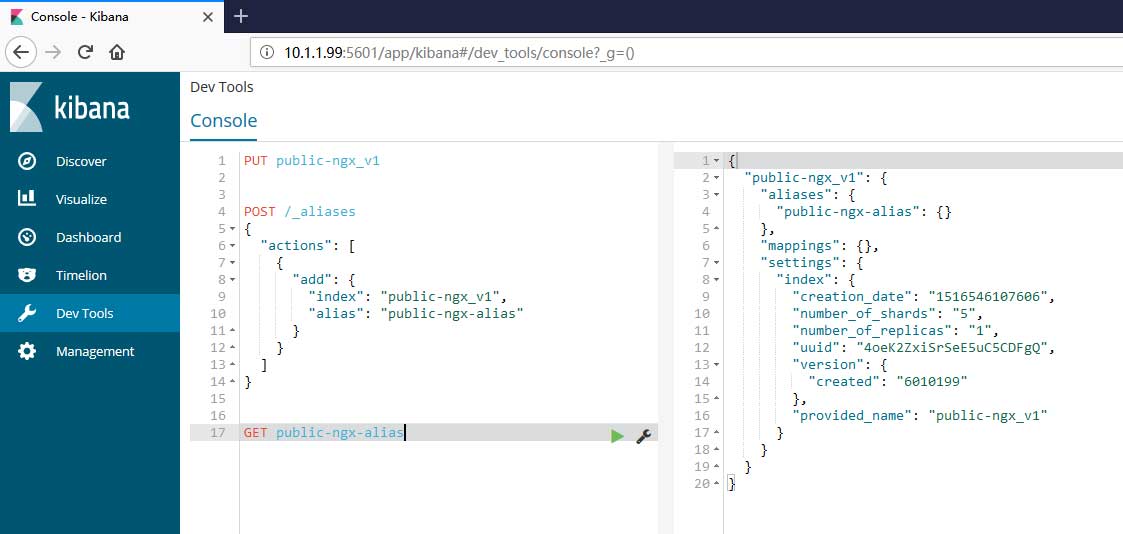
索引的创建于链接工作可通过kibana中dev_tools进行:
PUT public-ngx_v1 #或curl curl -XPUT "http://localhost:9200/public-ngx_v1"
别名的链接也可以使用该工具进行:
POST /_aliases
{
"actions": [
{
"add": {
"index": "public-ngx_v1",
"alias": "public-ngx-alias"
}
}
]
}
#或curl
curl -XPOST "http://localhost:9200/_aliases" -H 'Content-Type: application/json' -d'
{
"actions": [
{
"add": {
"index": "public-ngx_v1",
"alias": "public-ngx-alias"
}
}
]
}'

通过以下命令可以查看相关索引的信息:
GET public-ngx-alias #过curl curl -XGET "http://localhost:9200/public-ngx-alias"
完成后还需要为匹配“public-ngx_*”这个规则的实体索引配置模板,请注意!不要为虚拟索引配置模板!这是为了应对日后发生字段类型改变的情况,方便应用新的模板,并且重新匹配旧数据所设定的。具体可参考以下文章:
接下来是模板,以下是我目前匹配nginx日志的模板:
{
"aliases": {},
"index_patterns": [
"public-nginx_*"
],
"mappings": {
"doc": {
"properties": {
"bytes": {
"type": "long"
},
"client_ip": {
"type": "ip"
},
"geoip": {
"dynamic": true,
"properties": {
"location": {
"type": "geo_point"
}
},
"type": "object"
},
"request_time": {
"type": "float"
},
"upstream_response_time": {
"type": "float"
}
}
}
},
"order": 0,
"settings": {
"index": {
"number_of_shards": "5"
}
}
}
因为我系统中的日志较为简单且内容较少,所以模板也较为简单。但一般来说模板主要包含setting和mappings两部分内容。setting部分可以是以下这样的:
"settings": {
"number_of_shards": 1
},
以上设定了该索引只有1个分片,需要注意的是,一旦分片数量设定且索引已经生成,那么该数值不可再发生改变,除非重新生成索引!更多setting字段的内容请参考官方文档:
mapping部分主要是字段类型的映射,支持的字段类型可参考官方文档:
mapping中支持的设定请参考官方文档:
需要注意的是,如果需要做算术加减,请注意选择数字类型,例如字节(byte)等,还需要注意各种类型的数值范围。如果需要使用可视化地图,则需要注意geo_point这个格式:
"geoip": {
"dynamic": true,
"properties": {
"location": {
"type": "geo_point"
}
}
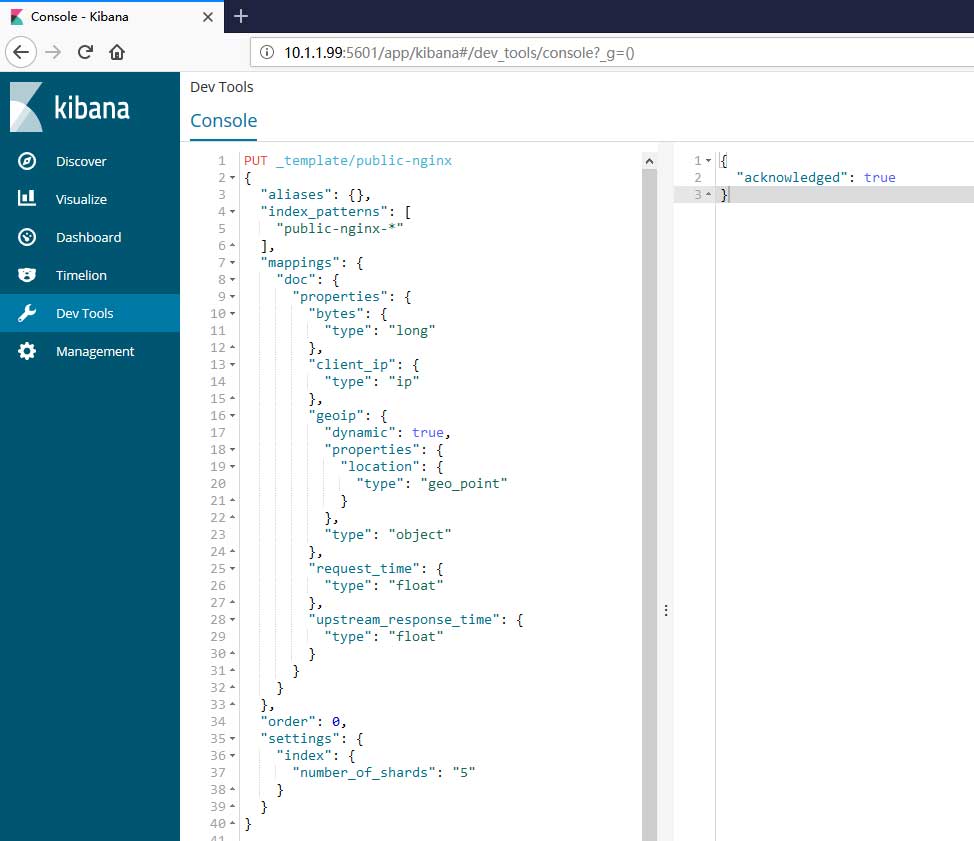
建立好模板后即可将其导入到elasticsearch中:
PUT _template/public-nginx
{
"aliases": {},
"index_patterns": [
"public-nginx-*"
],
"mappings": {
"doc": {
"properties": {
"bytes": {
"type": "long"
},
"client_ip": {
"type": "ip"
},
"geoip": {
"dynamic": true,
"properties": {
"location": {
"type": "geo_point"
}
},
"type": "object"
},
"request_time": {
"type": "float"
},
"upstream_response_time": {
"type": "float"
}
}
}
},
"order": 0,
"settings": {
"index": {
"number_of_shards": "5"
}
}
}
#或使用curl
curl -XPUT "http://localhost:9200/_template/public-nginx" -H 'Content-Type: application/json' -d'
{
"aliases": {},
"index_patterns": [
"public-nginx-*"
],
"mappings": {
"doc": {
"properties": {
"bytes": {
"type": "long"
},
"client_ip": {
"type": "ip"
},
"geoip": {
"dynamic": true,
"properties": {
"location": {
"type": "geo_point"
}
},
"type": "object"
},
"request_time": {
"type": "float"
},
"upstream_response_time": {
"type": "float"
}
}
}
},
"order": 0,
"settings": {
"index": {
"number_of_shards": "5"
}
}
}'
一切就绪后即可启动filebeat。
0x08 结语
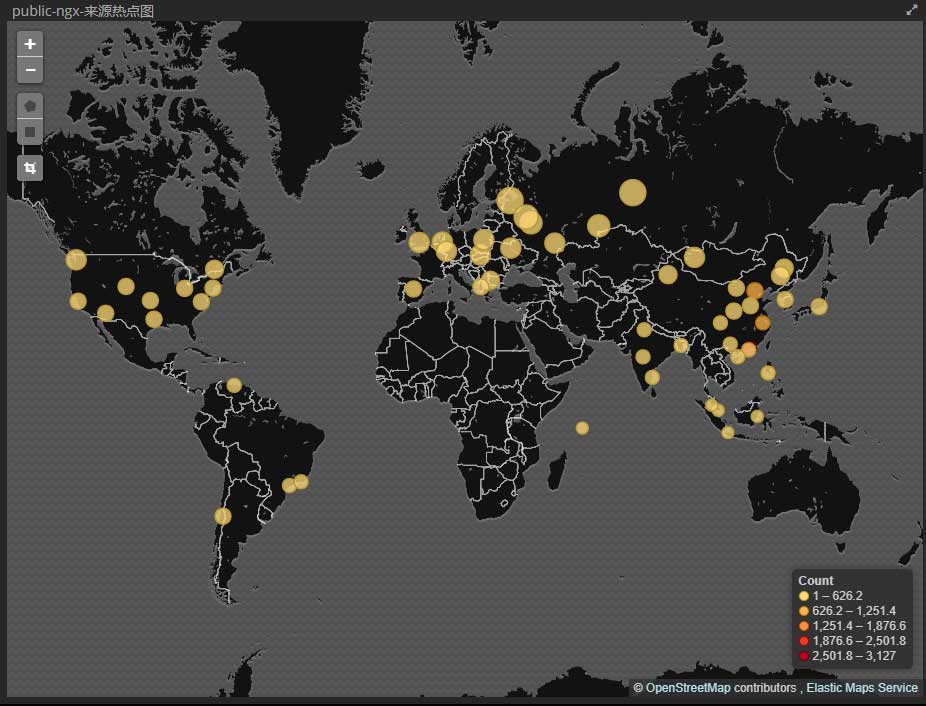
接下来只需要等待filebeat读取日志并传送至logstash,经过处理后的数据再传送到elasticsearch,最终打开kibana的Management –> Index Patterns添加虚拟索引:
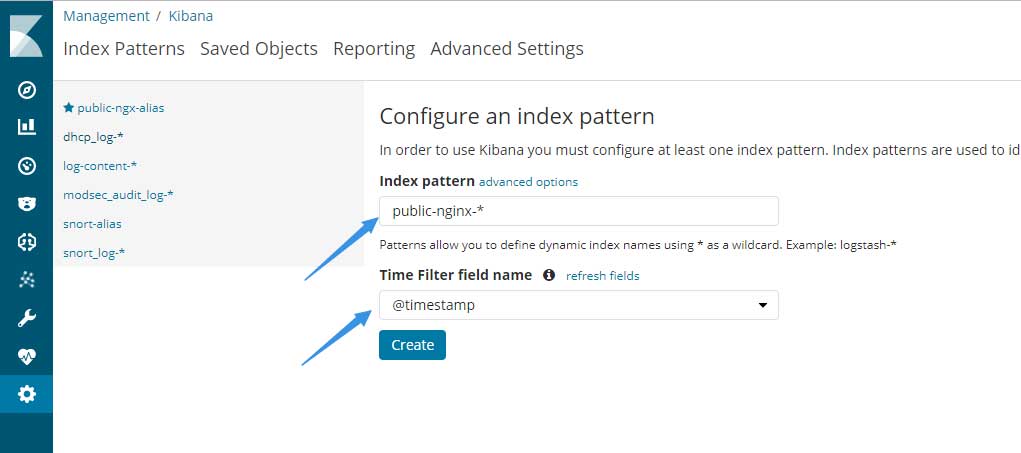
因为测试环境无数据,所以引用了生产环境中的一张截图
如果一切正常,那么在discover标签内看到的内容类似下图:

因上图内容较为敏感,所以做了模糊处理
elasticstack整体配置起来确实较为繁琐,尤其是logstash的部分,如果遇到多行日志则更加麻烦。如果需要处理上亿条的数据,建议建立elasticsearch集群,可加快检索速度。






















